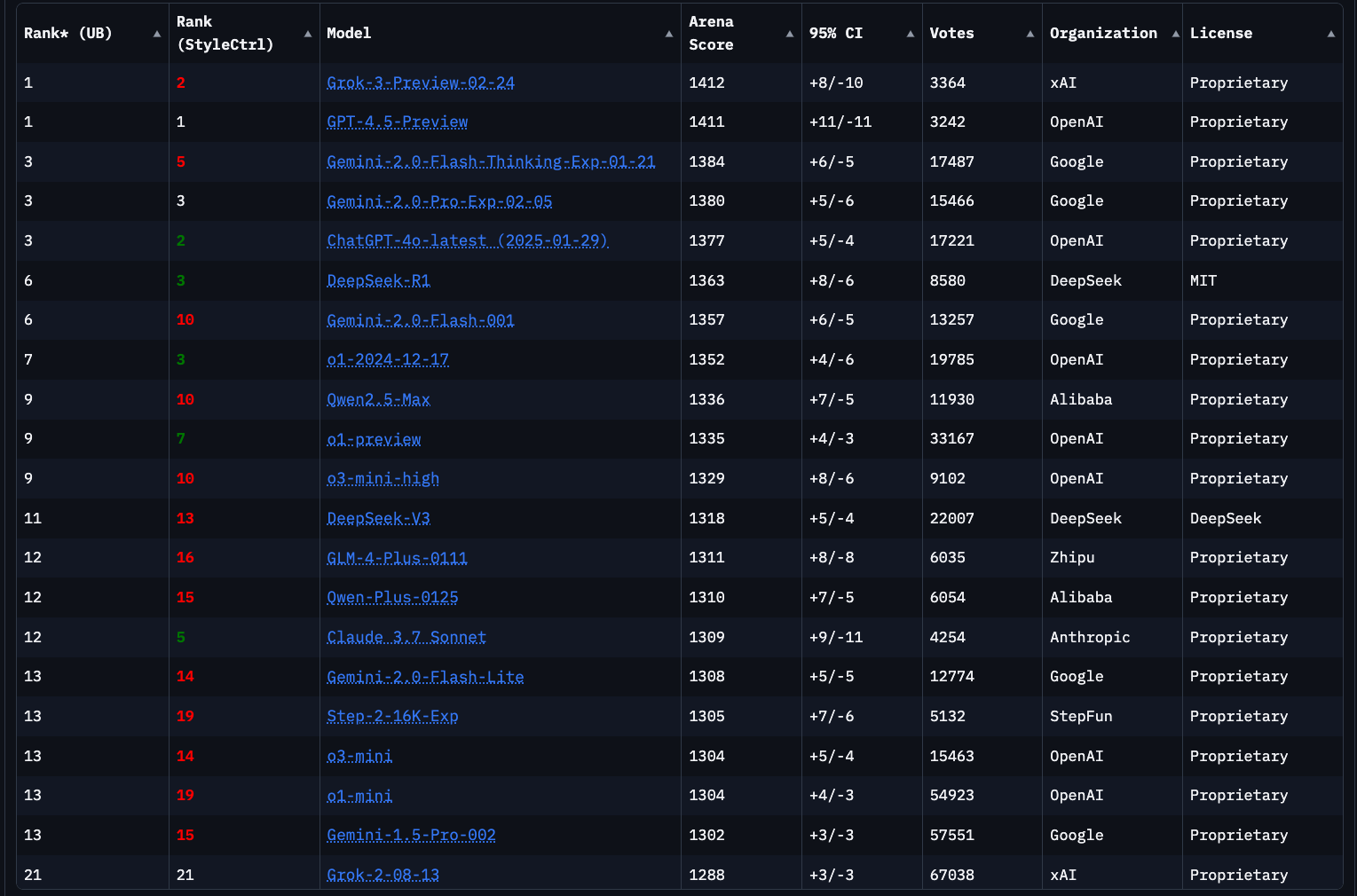
최근 AI 업계에서 가장 뜨거운 감자는 출시 직후만 해도 최상위권을 유지하던 플래그십 모델들이 시간이 지나며 사용자에게서 체감 성능이 떨어지는 현상입니다. 단순히 새로운 모델이 등장하면서 상대적 순위가 밀린 것이라기보다, 실제 모델의 내부 상태가 변질되었을 가능성에 대한 분석이 주목받고 있습니다. 특히 LMSYS 아레나와 같은 오픈 소스 리더보드 데이터를 기반으로 한 시각화 자료들은 특정 모델의 ELO 점수 추이를 추적하며, 이러한 성능 저하가 무작위적이지 않고 일정한 패턴을 보인다는 사실을 드러냈습니다.
이 현상의 핵심 원인으로 지목되는 것은 비용 효율성을 위한 ‘은밀한 약화’ 전략입니다. AI 연구소들은 모델 출시 후에도 API 엔드포인트를 통해 모델을 업데이트하거나, 고비용의 정밀도를 낮춘 양자화 버전을 몰래 적용하는 경우가 있습니다. 또한 사용자 경험의 안전성을 높이기 위해 과도한 검열 필터나 시스템 프롬프트를 추가하면, 원본 모델의 유연성이 떨어지고 답변의 질이 낮아지는 결과를 낳습니다. 웹 인터페이스와 API 간의 성능 차이는 바로 이러한 숨겨진 레이어들이 작용하기 때문에 발생하며, 벤치마크 점수만으로는 실제 사용 환경에서의 성능 저하를 온전히 포착하기 어렵습니다.
커뮤니티의 반응은 이 데이터가 단순한 통계 이상의 의미를 가진다는 데 집중되어 있습니다. 일부 개발자들은 아레나의 ELO 점수가 상대적 평가 시스템이기 때문에, 새로운 강자가 등장하면 기존 모델의 점수가 자연스럽게 하락하는 통계적 현상일 뿐이라고 지적합니다. 하지만 다른 관점에서는 특정 기업들이 모델의 성능을 유지하기보다 비용 절감에 더 집중하며 점진적으로 모델을 약화시키는 경향을 보인다는 주장이 설득력을 얻고 있습니다. 특히 중국계 모델들이 일관된 성능 향상을 보이는 반면, 서구권 주요 기업들의 모델은 성장이 정체되거나 오히려 하락세를 보이는 대조적인 흐름이 주목받습니다.
앞으로 주목해야 할 지점은 이러한 성능 변동이 단기적인 조정인지, 아니면 AI 산업의 구조적 변화인지를 가르는 기준이 될 것입니다. 만약 모델의 성능 저하가 비용 절감을 위한 전략적 선택이라면, 사용자는 더 이상 ‘최고의 모델’이라는 마케팅 문구에 맹신하기보다 실제 API 성능과 웹 인터페이스 간의 괴리를 면밀히 확인해야 할 것입니다. 또한 각 연구소가 모델의 수명 주기를 어떻게 관리하며, 투명하게 성능을 공개할 것인지에 따라 AI 시장의 경쟁 구도가 다시 바뀔 수 있습니다. 단순한 점수 추이를 넘어, 모델의 실제 생명 주기와 품질 유지 전략을 파악하는 것이 향후 AI 기술을 선택하는 데 중요한 기준이 될 것입니다.