현재 글로벌 AI 기술계에서 가장 뜨거운 감자는 단연 ‘확산형 언어모델(Diffusion Language Models)’의 등장이다. 그동안 대규모 언어모델(LLM)은 코드 생성부터 문서 요약까지 다양한 분야에서 표준으로 자리 잡았지만, 그 이면에는 치명적인 속도 한계가 존재했다. 기존 모델은 이전 토큰을 기반으로 다음 토큰을 하나씩 순차적으로 생성하는 자기회귀 방식에 의존해 왔다. 이 방식은 학습과 서빙이 안정적이라는 장점이 있었으나, 매번 새로운 토큰을 생성할 때마다 전체 모델 가중치를 메모리에서 불러와야 하는 구조적 부담을 안고 있었다. 결과적으로 현대 GPU의 연산 능력 대부분이 실제 계산보다는 메모리 이동에 소모되는 비효율이 발생하며, 지연 시간에 민감한 애플리케이션 개발자들에게는 큰 걸림돌이 되어 왔다.
이러한 배경 속에서 나이비디아의 ‘네모트론 랩스 확산형 모델’이 주목받는 이유는 바로 이 병목 현상을 근본적으로 해결할 가능성을 제시했기 때문이다. 확산형 언어모델은 토큰을 한 번에 생성하거나, 생성된 토큰을 추후에 수정하고 보완할 수 있는 유연성을 제공한다. 이는 마치 이미지 생성 모델이 노이즈에서 선명한 그림을 만들어내는 과정과 유사하게, 텍스트 생성 과정에서도 초기 불완전한 상태를 점진적으로 정제해 나가는 방식을 취한다. 기존 방식에서는 한 번 생성된 토큰이 최종 결정되어 오류가 전파되기 쉽다면, 확산형 모델은 생성 과정 중에도 이전 토큰을 재검토하고 수정할 수 있어 정확도와 유연성을 동시에 잡을 수 있는 구조를 갖췄다.
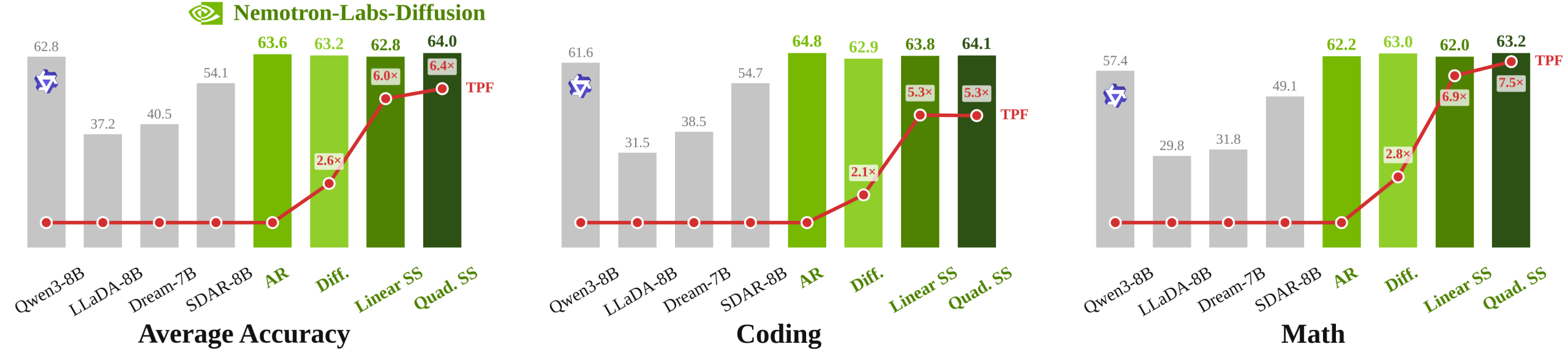
실제 성능 지표에서도 이 모델은 기존 방식의 한계를 넘어서는 가능성을 보여주고 있다. 특히 SGLang 같은 최신 추론 엔진과 결합되었을 때, 메모리 대역폭에 의존하던 기존 방식과 달리 연산 효율성을 극대화하여 GPU 자원을 훨씬 더 효과적으로 활용할 수 있다. 이는 단순히 텍스트 생성 속도가 빨라지는 것을 넘어, 작은 배치 크기로도 고성능 추론이 가능해짐을 의미한다. 개발자들은 더 적은 하드웨어 투자로 더 빠른 응답 속도를 얻을 수 있게 되며, 실시간성이 요구되는 대화형 에이전트나 복잡한 코드 생성 작업에서 체감되는 지연 시간을 획기적으로 줄일 수 있게 된다.
이제 주목해야 할 점은 확산형 언어모델이 실제 상용 환경에서 얼마나 빠르게 표준으로 자리 잡을 것인가이다. 아직은 초기 단계이지만, 이 기술이 가진 잠재력은 단순한 속도 개선을 넘어 언어모델의 아키텍처 자체를 재정의할 수 있는 힘을 가지고 있다. 향후 몇 달 내에 더 많은 모델이 확산 방식을 채택하거나, 기존 자기회귀 모델과의 하이브리드 형태가 등장할 가능성이 높다. 기술적 완성도가 높아진다면, 우리가 일상에서 사용하는 AI 서비스의 반응 속도는 현재와 비교할 수 없을 만큼 빨라질 것이며, 이는 AI 기술이 더 복잡한 실시간 업무 환경으로 확장되는 결정적인 계기가 될 것이다.