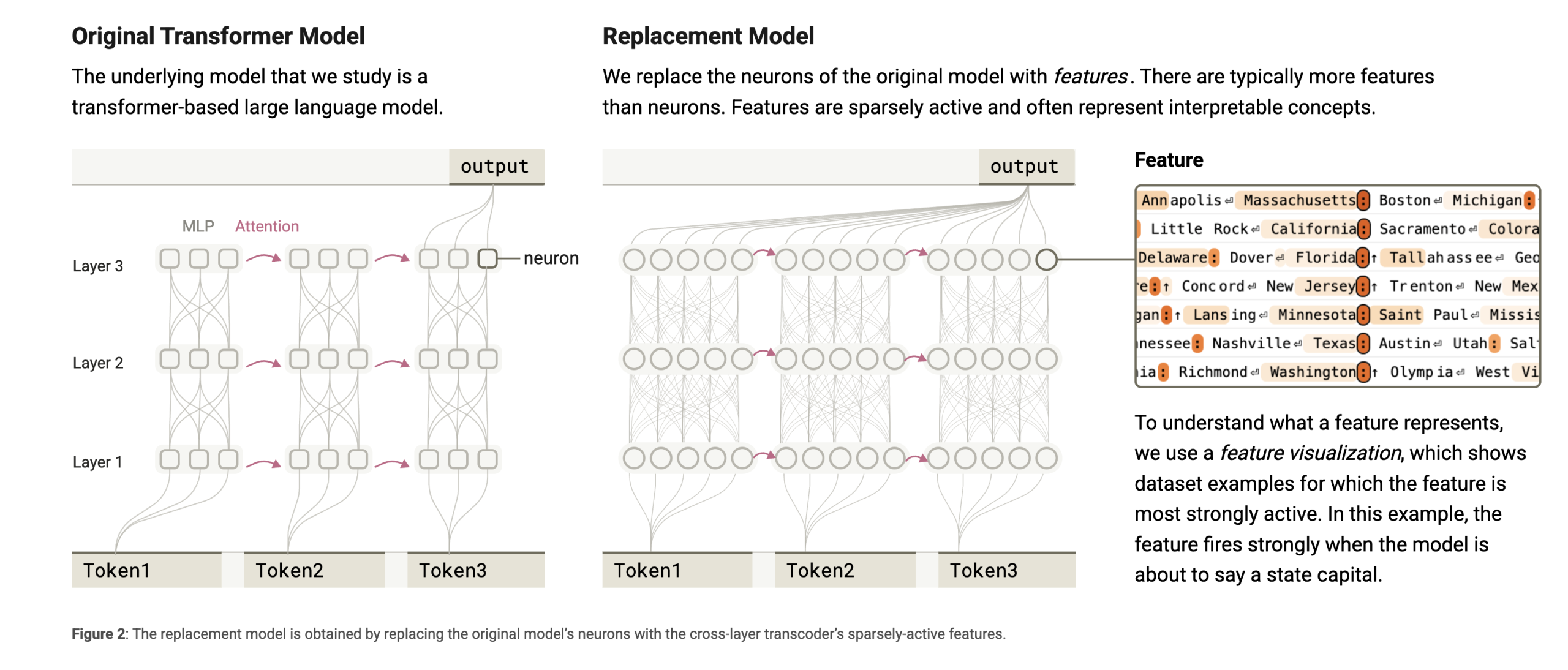
인공지능이 마치 신비로운 블랙박스처럼 작동한다는 통념이 빠르게 무너져 내리고 있습니다. 과거에는 거대 언어 모델이 내부에서 어떤 논리를 거쳐 답을 도출하는지 알 수 없다는 것이 정설이었습니다.
하지만 최근 기술적 진보로 인해 이 막연한 불확실성이 구체적인 해석 가능성으로 바뀌고 있습니다.
특히 앤스로픽의 최신 연구는 언어 모델의 내부 회로를 추적하는 기계적 해석 가능성 분야에서 획기적인 진전을 보였습니다. 연구팀은 모델이 Dallas 같은 특정 지명이나 올림픽 같은 개념을 어떻게 처리하는지 단계별로 관찰할 수 있게 되었습니다.
단순히 뉴런의 활성화 상태를 보는 것을 넘어, 실제 추론 과정에 관여하는 개념들의 연결 고리를 찾아낸 것입니다.
이러한 변화는 모델이 단순히 확률적으로 다음 단어를 예측하는 것을 넘어, 인간이 이해할 수 있는 논리적 단계를 거치며 사고할 수 있음을 시사합니다. 예를 들어 시를 지을 때 rhyming 후보를 미리 고려하는 등 미래 단계를 예측하는 과정까지 내부 회로에서 포착되었습니다.
이는 AI가 마치 생물학적 뇌처럼 복잡한 개념들을 조합하여 문제를 해결한다는 증거로 받아들여지고 있습니다.
실제 커뮤니티에서는 이러한 발견이 AI의 투명성을 높이고 위험한 의도를 사전에 감지하는 데 큰 도움이 될 것이라는 기대감이 커지고 있습니다. 특히 모델의 행동을 직접 조종하거나 특정 개념을 강화하는 등 정밀한 제어가 가능해질 것이라는 전망이 지배적입니다.
이는 단순한 기술적 호기심을 넘어 실제 산업 현장에서의 활용도를 높이는 핵심 열쇠가 될 것입니다.
앞으로 주목해야 할 점은 이러한 해석 가능성이 확산 모델 등 다른 생성 모델에도 적용될 수 있는지 여부입니다. 또한 인간이 인위적으로 만든 개념이 아니라 모델 내부에서 자연스럽게 발견되는 개념들이 얼마나 많은지도 중요한 관전 포인트입니다.
AI가 더 이상 검은 상자가 아니라, 우리가 그 속을 들여다보고 이해할 수 있는 투명한 시스템으로 진화하는 과정이 본격화되고 있습니다.






