최근 rsync 라는 오래된 파일 동기화 도구를 둘러싸고 개발자 커뮤니티가 뜨겁게 달아올랐습니다. 핵심 쟁점은 바로 AI 모델인 클로드가 작성한 코드가 기존 버그 수를 불렀다는 의문입니다.
단순한 통계 분석을 넘어, 인공지능이 핵심 인프라에 개입했을 때 발생할 수 있는 예상치 못한 부작용에 대한 우려가 현실로 다가온 셈입니다.
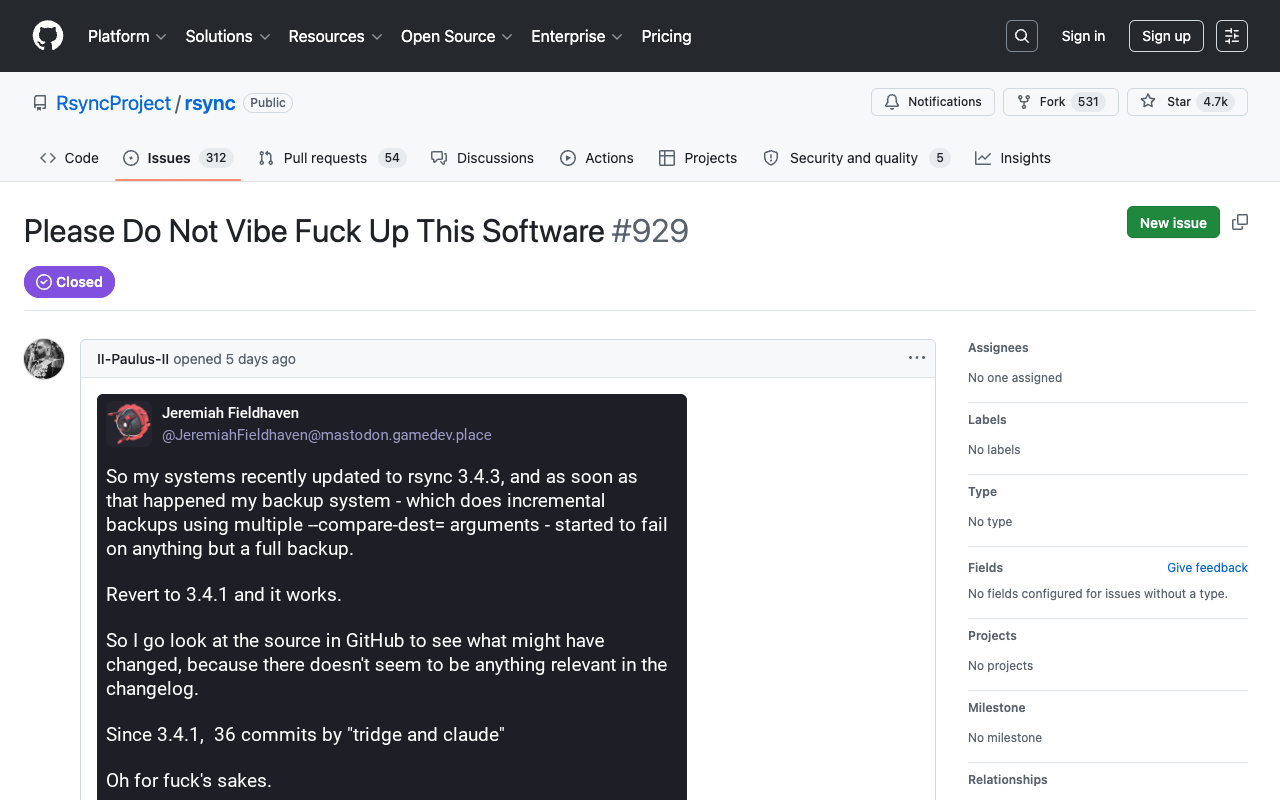
논란의 시초는 rsync 의 특정 커밋과 그 되돌림 과정을 분석한 한 개발자의 발견에서 시작되었습니다. 클로드가 작성한 코드가 메모리 할당 방식을 무리하게 통일하려다 성능 저하를 초래했다는 지적이 나왔습니다.
이 코드는 할당된 모든 메모리를 calloc 함수로 강제 변환했는데, 이는 대규모 재귀적 할당 상황에서 불필요한 오버헤드를 만들어냈습니다. 결국 이 변경 사항은 출시 직후 곧바로 되돌려졌고, 그 과정에서도 AI 특유의 뉘앙스가 느껴진다는 후문입니다.
이 사건이 단순한 코드 실수를 넘어 주목받는 이유는 분석 방법론의 신빙성 때문입니다. 통계학 전공자를 둔 저자가 수작업으로 데이터를 수집하고, 과거 릴리스의 버그 분포와 비교하는 정교한 방식을 택했습니다.
단순히 코드 줄 수 대비 버그 수를 비교하는 대신, 역사적 데이터 분포 안에서 AI 가 관여한 릴리스가 얼마나 이례적인 위치에 있는지 확인했습니다. 이 과정에서 AI 가 개입한 버전이 과거 평균보다 훨씬 높은 버그 수를 보였다는 결론이 도출되면서, AI 코드에 대한 경계심이 커졌습니다.
하지만 이 분석을 둘러싼 반응은 엇갈립니다. 일부는 통계적 편향 가능성을 지적하며, 최근 릴리스는 아직 시간이 부족해 버그가 완전히 드러나지 않았을 수 있다고 반박합니다.
또한, 특정 버전의 수명이 길어 그 사이에 발생한 버그가 모두 해당 버전의 탓으로 돌아가는 방법론적 한계도 존재합니다. 그럼에도 불구하고, AI 가 생성한 코드가 겉보기엔 완벽해 보이지만 내부적으로는 미세한 결함을 품고 있을 수 있다는 경고는 개발자들에게 큰 울림을 주었습니다.
이 논란은 앞으로 소프트웨어 공급망의 안전성을 어떻게 지켜야 할지에 대한 새로운 질문을 던집니다. AI 가 코드를 작성하는 속도가 빨라질수록, 인간 개발자의 감시와 검증 프로세스가 더 정교해져야 한다는 점이 부각됩니다.
단순한 자동화를 넘어, AI 가 만든 코드가 실제 시스템에 어떤 영향을 미치는지 면밀히 추적하는 습관이 새로운 표준이 될 가능성이 큽니다. 이제 우리는 AI 가 쓴 코드를 맹신하기보다, 그 이면에 숨은 위험을 읽어내는 눈이 필요한 시점에 서 있습니다.