최근 글로벌 AI 개발자 커뮤니티를 뜨겁게 달구고 있는 키워드는 바로 딥시크 R1 의 완전한 오픈 복제입니다. 기존에 폐쇄적으로 운영되던 대형 모델의 학습 과정과 추론 능력을 누구나 검증 가능한 형태로 공개하려는 움직임이 본격화되면서 주목을 받고 있습니다.
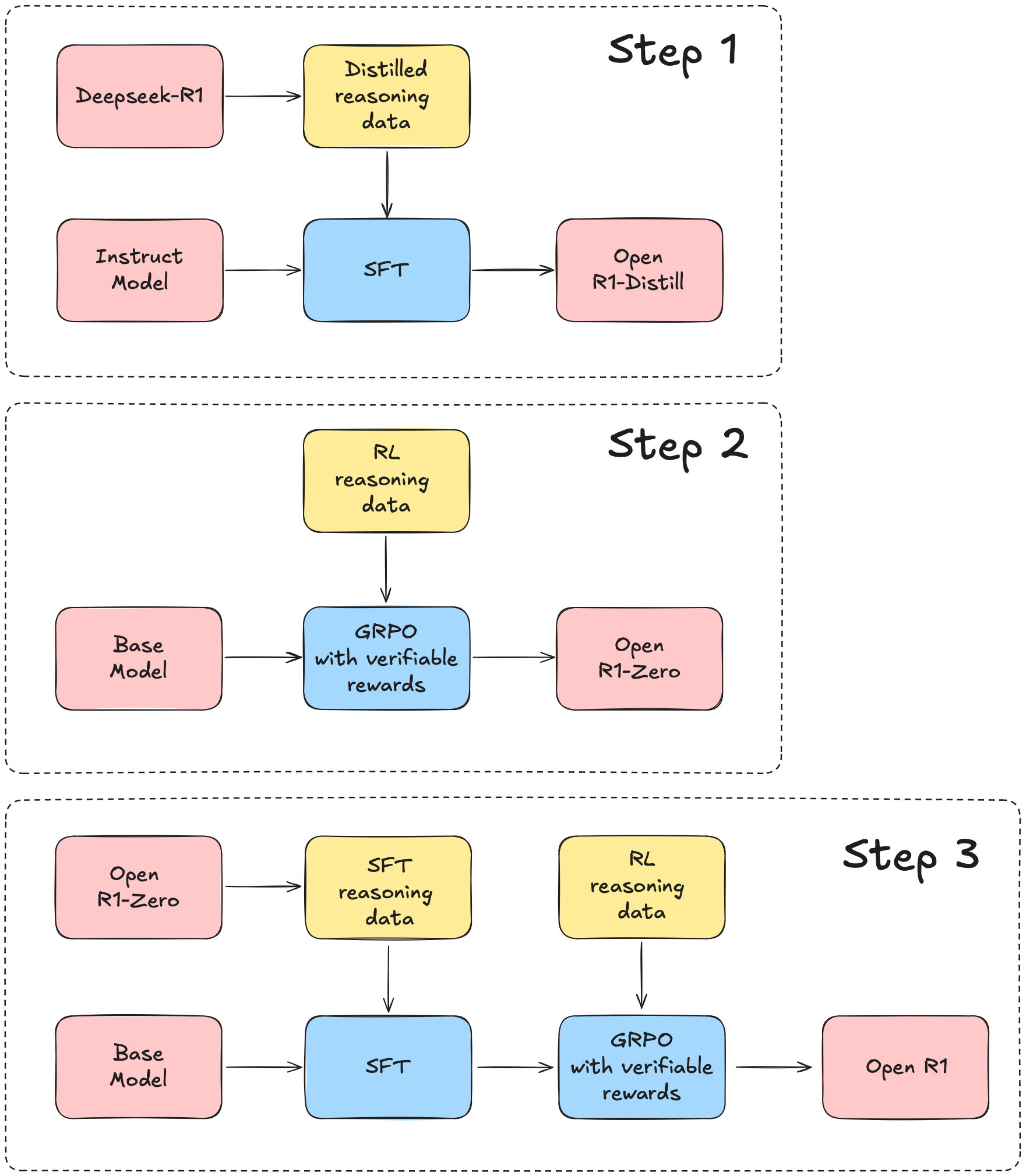
허깅페이스가 주도하는 오픈 R1 프로젝트는 이 흐름의 중심에 서 있습니다. 이 저장소는 단순히 모델을 배포하는 것을 넘어, 데이터 생성부터 학습 파이프라인까지 전 과정을 투명하게 재현하려는 목표를 가지고 있습니다.
개발자들은 이를 통해 딥시크가 보여준 놀라운 추론 능력을 직접 분석하고 개선해 나갈 수 있게 되었습니다.
특히 주목할 점은 2025 년 5 월에 발표된 첫 번째 단계의 성과입니다. 수학, 코딩, 과학 분야를 아우르는 35 만 개의 검증된 추론 데이터셋이 공개되면서, 작은 규모의 모델도 복잡한 논리 문제를 단계별로 풀 수 있는 능력을 갖추게 되었습니다.
이는 단순히 모델을 베끼는 것을 넘어, 어떻게 하면 효율적으로 추론 능력을 배양할 수 있는지에 대한 구체적인 레시피를 제시한 셈입니다.
하지만 커뮤니티 안에서는 여전히 회의적인 시선도 존재합니다. 일부 전문가들은 현재 공개된 내용이 전체 계획 중 첫 단계에 불과하며, 진정한 의미의 완전한 재현을 위해서는 더 많은 데이터와 학습 비용이 필요하다고 지적합니다.
올모나 네모트론처럼 이미 완전한 오픈 파이프라인을 갖춘 모델들과 비교했을 때 아직 갈 길이 멀다는 평가도 나옵니다.
이러한 흐름이 중요한 이유는 AI 기술의 발전 방향이 이제 ‘누가 더 큰 모델을 만들었는가’에서 ‘어떻게 그 능력을 투명하게 증명할 것인가’로 바뀌고 있기 때문입니다. 앞으로 이 프로젝트가 어떻게 진화할지, 그리고 오픈 소스 기반의 추론 모델이 상용 모델을 얼마나 따라잡을지 지켜보는 것이 다음 트렌드를 읽는 핵심 열쇠가 될 것입니다.