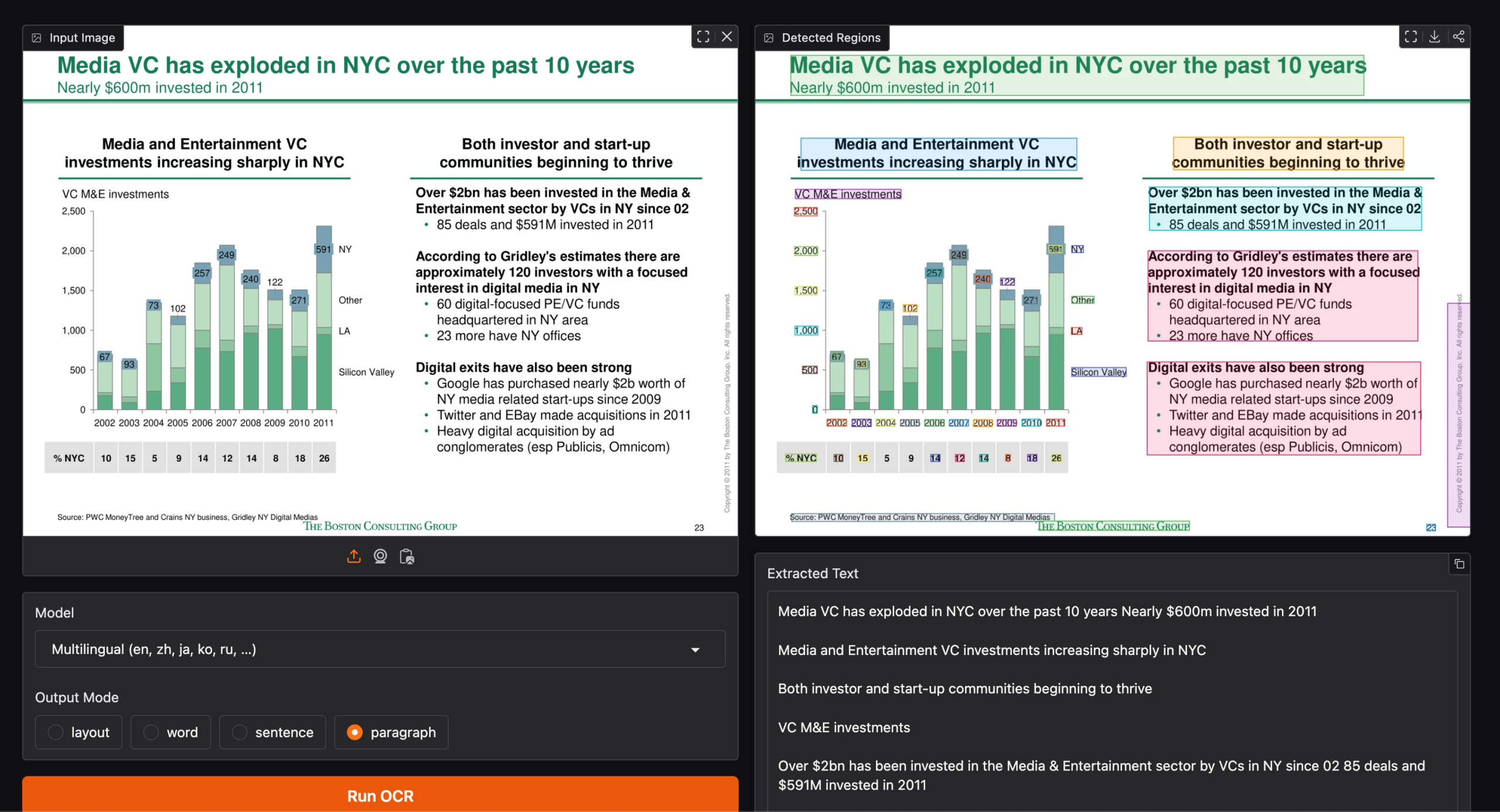
최근 텍스트 인식 기술 분야에서 가장 뜨거운 이슈는 단순히 더 많은 데이터를 모으는 것이 아니라, 어떻게 하면 적은 데이터로도 다양한 언어를 빠르고 정확하게 처리할 수 있을지에 대한 고민입니다. 기존 OCR 모델들은 영어와 중국어 위주로 편향된 데이터셋에 의존하거나, 수작업으로 라벨링된 고품질 데이터를 확보하기 위해 막대한 비용과 시간을 소모해 왔습니다. 하지만 이제 이 같은 방식의 한계를 뛰어넘는 새로운 접근법이 주목받고 있습니다.
핵심은 데이터의 양보다 데이터의 질과 생성 방식, 그리고 이를 처리하는 모델의 구조에 있습니다. NVIDIA 가 Hugging Face 를 통해 공개한 네모트론 OCR v2 는 이 흐름을 선도하는 대표 사례입니다. 이 모델은 실제 이미지 대신 합성 데이터를 활용하여 학습함으로써, 특정 언어에 치우치지 않고 전 세계 다양한 언어를 아우르는 범용성을 확보했습니다. 특히 mOSCAR 과 수정된 SynthDoG 파이프라인을 통해 생성된 데이터는 실제 문서의 복잡한 레이아웃과 다양한 폰트 변형을 자연스럽게 반영하면서도, 수백만 장 규모로 확장 가능한 장점을 보여줍니다.
가장 주목할 점은 이 모델이 보여주는 압도적인 처리 속도입니다. 많은 사람이 고성능 OCR 모델을 만들면 속도가 느려질 것이라고 예상하지만, 네모트론 OCR v2 는 FOTS 아키텍처를 기반으로 detection 과 recognition 을 단일 네트워크로 통합했습니다. RegNetX-8GF 백본이 입력 이미지를 한 번만 처리하여 생성한 특징 맵을 세 가지 구성 요소가 공유하는 방식입니다. 이렇게 무거운 합성 연산을 한 번만 거치고 하위 구성 요소들이 이를 재사용함으로써 불필요한 오버헤드를 극도로 줄였습니다. 그 결과 단일 A100 GPU 환경에서 초당 34.7 페이지를 처리할 수 있는 효율성을 입증했습니다.
실제 성능 검증에서도 이 모델은 SynthDoG 멀티링구얼 벤치마크와 OmniDocBench 같은 실세계 벤치마크에서 기존 방식보다 우수한 결과를 기록했습니다. 이는 단순히 이론적인 효율이 아니라, 실제 문서 처리 환경에서도 즉시 적용 가능한 실용성을 의미합니다. 앞으로 OCR 기술은 더 이상 방대한 데이터 수집 경쟁을 벌이기보다, 합성 데이터의 정교한 제어와 아키텍처의 효율성 극대화를 통해 어떤 언어든 빠르고 정확하게 읽어내는 방향으로 진화할 것입니다. 개발자와 기업들은 이제 데이터 라벨링 비용에 매몰되기보다, 이러한 합성 데이터 파이프라인과 효율적인 모델 구조를 어떻게 도입할지 고민해야 할 시점이 왔습니다.