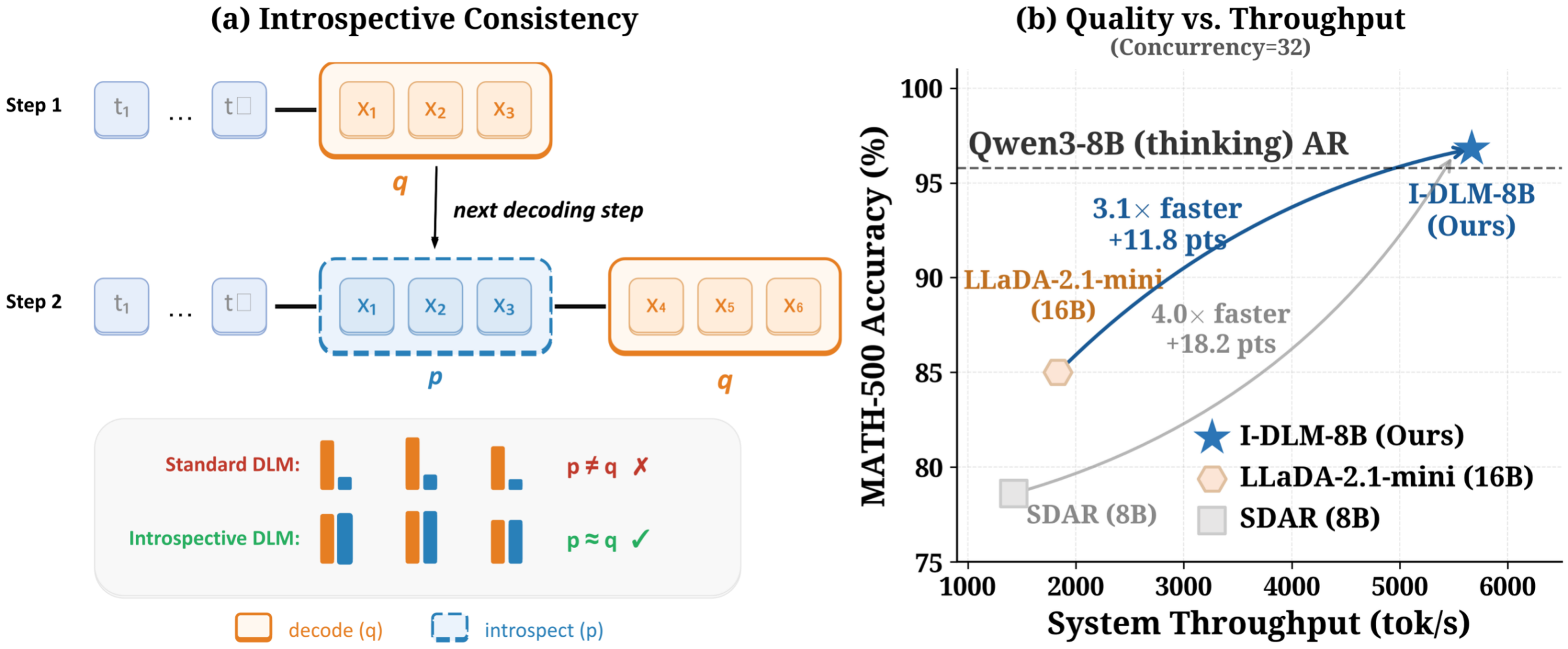
오랜 시간 동안 언어 모델의 확산 기법은 병렬 생성이라는 매력적인 잠재력을 내세웠지만, 실제 품질 면에서는 순차적으로 단어를 이어가는 자동회귀 방식에 밀려왔습니다. 하지만 최근 등장한 ‘내성적 확산 언어 모델’이 이 오랜 격차를 해소하며 기술계의 이목을 집중시키고 있습니다. 핵심은 모델이 자신이 생성한 토큰을 다시 한번 검증하는 내성적 일관성이라는 개념을 도입한 데서 시작됩니다. 기존 확산 모델은 생성 과정에서 자신의 이전 출력을 충분히 수용하지 못해 품질 저하가 발생했지만, 새로운 접근법은 생성과 검증을 동시에 수행하며 자동회귀 모델이 가진 구조적 우위를 흡수했습니다.
이 기술이 주목받는 이유는 단순한 이론적 호기심을 넘어 실질적인 성능 지표에서 압도적인 결과를 보여주기 때문입니다. 연구 결과에 따르면, 동급의 자동회귀 모델과 품질을 견줄 뿐만 아니라 기존 확산 모델 대비 3 배에 가까운 처리량을 기록했습니다. 특히 수학 문제 해결이나 코딩 벤치마크에서 기존 확산 모델들을 크게 앞지르는 수치를 보이며, 병렬 처리의 한계를 실질적으로 깨뜨렸다는 평가를 받습니다. 이는 메모리 대역폭에 의존하던 기존 방식에서 계산 능력으로 병목이 이동했음을 시사하며, 대규모 동시 접속 환경에서도 효율적인 서빙이 가능해졌음을 의미합니다.
커뮤니티 반응은 기술적 세부 사항보다는 실제 적용 가능성에 집중되어 있습니다. 개발자들은 기존에 훈련된 자동회귀 모델을 확산 방식으로 전환하면서도 원본 모델의 출력과 비트 단위로 일치하는 결과를 얻을 수 있다는 점에 놀라움을 표합니다. 특히 LoRA 어댑터를 통해 베이스 모델의 분포를 고정하면, 동일한 시드에서 정확히 같은 텍스트를 더 빠른 속도로 생성할 수 있어 실용성이 매우 높다는 평이 지배적입니다. 이는 추론 속도를 획기적으로 높이는 동시에 품질 저하 없이 병렬화의 이점을 누릴 수 있는 첫 번째 사례로 기록되고 있습니다.
앞으로 주목해야 할 점은 이 기술이 어떻게 실제 서비스 환경에 통합될지입니다. 기존 인프라를 크게 변경하지 않고도 SGLang 같은 시스템에 직접 통합될 수 있다는 점은 상용화 장벽을 낮추는 중요한 요소입니다. 또한, 생성 블록을 만들고 이를 내성적으로 검토한 후 다음 블록을 생성하는 방식이 복잡한 추론 단계에서도 유효한지 여부는 향후 검증될 중요한 화두가 될 것입니다. 확산 모델이 이제 단순한 실험실의 신기한 장난감이 아닌, 실제 생산성을 높이는 핵심 엔진으로 자리 잡을지 지켜보는 시기가 되었습니다.