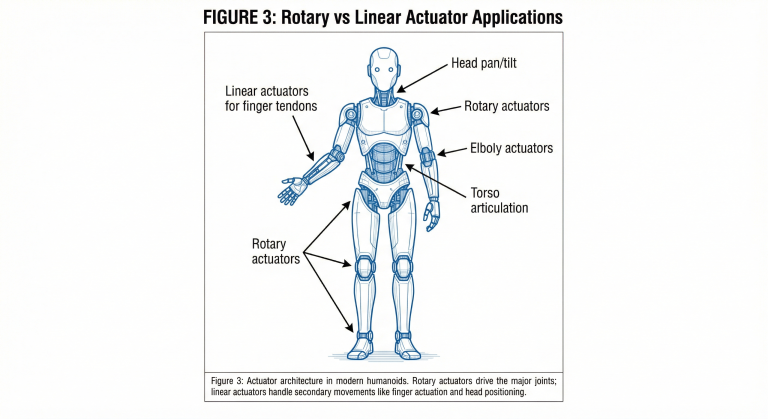
최근 개발자 커뮤니티를 뜨겁게 달구는 주제는 역설적인 현상에서 시작됩니다. 소프트웨어 추상화가 발전할수록 개발자는 더 많은 자유를 얻는 듯하지만, 정작 시스템의 내부 구조를 이해하는 능력은 오히려 퇴보하고 있다는 사실입니다. 과거에는 메모리와 연산 자원이 귀했기에 개발자들은 CPU 사이클 하나하나를 신경 쓰며 정밀한 코드를 작성해야 했습니다. 하지만 현대의 풍부한 컴퓨팅 파워는 복잡한 로직을 감추는 추상화 계층을 무분별하게 쌓아 올리게 만들었고, 이는 개발자가 기계와 직접 대화하던 친밀한 관계를 단절시켰습니다.
이러한 추상화의 확대는 분명히 진입 장벽을 낮추고 개발 속도를 높이는 긍정적 효과를 가져왔습니다. 하지만 그 이면에는 기술적 충실도가 떨어지는 대가가 숨어 있습니다. 타인이 작성한 라이브러리에 의존하는 비중이 커지면서, 내부 동작 원리를 모른 채 코드를 조립하는 경우가 빈번해졌습니다. 결과적으로 기능은 작동하지만 비효율적이거나 버그가 숨어 있는 소프트웨어가 양산되는 역설이 발생하고 있습니다. 특히 대규모 언어 모델을 활용한 AI 기반 개발이 보편화되면서, 비전문가도 기능적인 코드를 쉽게 생성할 수 있게 되었지만, 그 코드가 최상의 품질인지 판단하는 눈은 여전히 전문가에게만 남아 있습니다.
커뮤니티의 반응은 이 변화에 대한 우려와 함께 현실적인 고민으로 이어지고 있습니다. 많은 개발자가 AI 도구를 활용해 이력서를 작성하고 포트폴리오를 완성하지만, 정작 면접이나 실제 업무에서 기술적 깊이를 요구받으면 허를 찔리는 상황을 경험하고 있습니다. 기업들은 AI로 생성된 가짜 경력이나 과장된 기술 스택이 난립하는 ‘이력서 사기’ 현상에 직면해 있으며, 온라인 지원만으로는 진짜 역량을 가진 인재를 가려내기 어려워졌습니다. 이는 1990 년대 스팸 메일이 범람하던 시절을 연상시키며, 채용 시장의 신뢰도를 떨어뜨리는 새로운 장벽으로 작용하고 있습니다.
앞으로 주목해야 할 점은 ‘충분함’과 ‘완벽함’ 사이의 기준이 어떻게 재설정될 것인지입니다. 사소한 업무에는 ‘그럭저럭’ 작동하는 소프트웨어가 suffice 하지만, 핵심 인프라나 대규모 시스템에서는 비효율적인 추상화가 치명적인 병목 현상을 초래할 수 있습니다. 하드웨어가 저렴해졌다는 명목으로 비효율적인 코드를 양산하던 과거의 실수가, 이제는 고사양 장비에서도 성능 저하로 이어지는 아이러니를 낳고 있습니다. 개발자와 기업 모두 편리함 뒤에 숨은 기술적 비용을 인지하고, 추상화의 혜택을 누리면서도 근본적인 이해를 잃지 않는 균형을 찾아야 할 시점입니다.