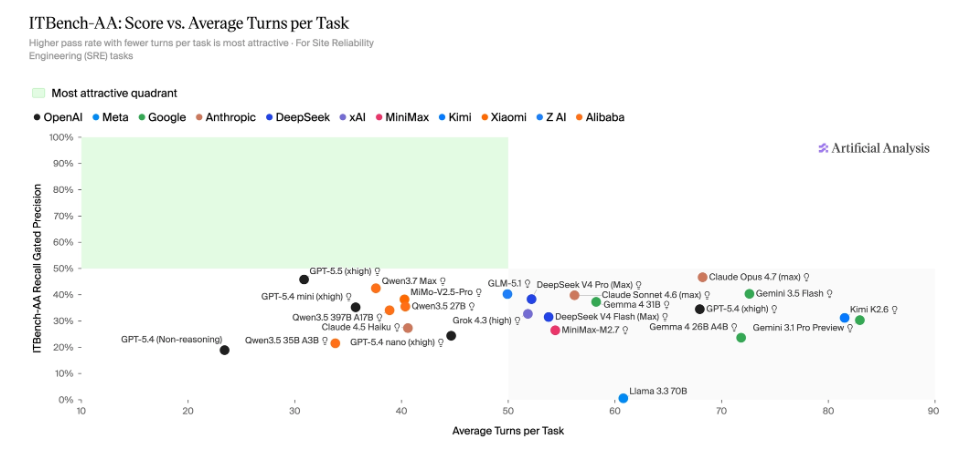
최첨단 AI 모델들이 일상적인 대화나 단순한 추론에서는 인간을 압도하는 성능을 보여주지만, 실제 기업 환경의 복잡한 IT 운영 과제를 수행할 때는 예상치 못한 한계를 드러내고 있습니다. 최근 IBM 연구소와 Artificial Analysis 가 공동으로 공개한 ‘ITBench-AA’ 벤치마크 결과는 AI 업계에 큰 파장을 일으켰습니다. 이 벤치마크는 사이트 신뢰성 엔지니어링(SRE)을 중심으로 실제 시스템 장애 대응 능력을 평가하는데, 현재 시중에서 가장 성능이 뛰어난 프런티어 모델들조차 평균 50% 미만의 점수에 그쳤기 때문입니다.
이 벤치마크가 주목받는 핵심 이유는 기존 평가 기준과 달리 실제 인프라 환경에서 발생하는 동적 문제를 해결하는 능력을 측정하기 때문입니다. 모델들은 쿠버네티스 환경에서 실시간 로그를 분석하고, 의존성을 추적하며, 복잡한 시스템 구조 속에서 근본 원인을 찾아내야 합니다. 이러한 과제는 단순히 정답을 맞추는 것을 넘어, 여러 단계를 거치며 상황을 파악하고 행동하는 에이전트적 사고가 필수적입니다. 하지만 현재 최고 수준으로 평가받는 모델들도 이 복잡한 시나리오에서 50%를 넘지 못해, 실제 기업 도입 시 기대했던 수준의 자율성을 아직 확보하지 못했음을 시사합니다.
성능 데이터를 자세히 살펴보면 흥미로운 역설이 발견됩니다. 클로드 오퍼스 4.7 이 47% 로 1 위를 기록했지만, 이는 여전히 절반도 채 되지 않는 수치입니다. 그 뒤를 이어 GPT-5.5 가 46%, Qwen3.7 Max 가 42% 를 기록했습니다. 특히 흥미로운 점은 처리 과정의 길이와 정확도 사이의 관계입니다. GPT-5.5 는 평균 31 회 턴으로 46% 의 정확도를 보인 반면, 제미니 3.1 프로 프리뷰는 83 회라는 긴 턴을 거치면서도 30% 에 그쳤습니다. 이는 단순히 더 많은思考和와 시도, 즉 더 긴 경로를 만든다고 해서 문제 해결 능력이 비례하여 향상되지 않음을 의미합니다.
이러한 결과는 AI 모델이 실제 기업 환경에 투입되기 위해 넘어야 할 장벽이 생각보다 높다는 것을 보여줍니다. 기존에 알려진 터미널 벤치마크 등에서는 높은 점수를 기록했던 모델들이 ITBench-AA 에서는 상대적으로 낮은 점수를 보인 것은, 단순한 지식 습득이나 정적 문제 해결과 달리 동적인 시스템 관리에는 여전히 AI 의 추론 능력이 부족함을 방증합니다. 향후 금융 운영이나 최고 정보 보안 책임자 업무 등으로 평가 범위가 확장될 예정인 만큼, 이 벤치마크 결과가 향후 AI 모델 개발 방향과 기업들의 도입 전략에 어떤 영향을 미칠지 주목해야 합니다. AI 가 진정한 ‘에이전트’로 거듭나기 위해서는 단순한 성능 지표를 넘어 실제 복잡한 환경에서의 안정성이 검증되어야 할 시점입니다.