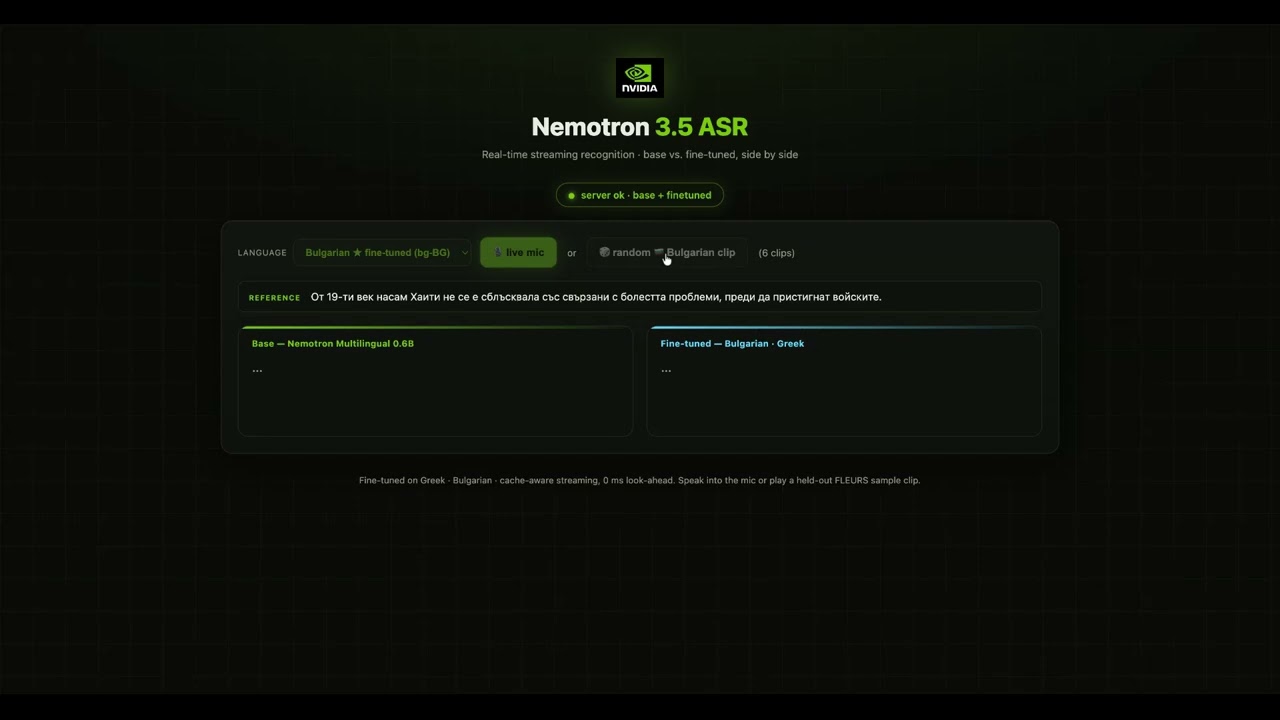
글로벌 AI 시장에서 실시간 음성 인식 기술의 패러다임이 빠르게 바뀌고 있습니다. NVIDIA 가 최근 Hugging Face 를 통해 공개한 네모트론 3.5 ASR 모델은 기존 방식의 한계를 명확히 보여주는 사례로 주목받고 있습니다.
이 모델은 단일 체크포인트에서 40 개 언어와 방언을 실시간으로 변환할 수 있는 능력을 갖췄습니다. 특히 문장 부호와 대문자 처리까지 내장된 상태에서 스트리밍이 가능하다는 점이 핵심입니다.
기존의 다국어 음성 인식 시스템은 종종 정확도와 속도 사이에서 선택을 강요받곤 했습니다. 한쪽을 높이면 다른 쪽이 떨어지는 트레이드오프 관계가 일반적이었죠.
하지만 네모트론 3.5 는 캐시 인식형 FastConformer-RNNT 아키텍처를 도입해 이 문제를 해결했습니다. 불필요한 재계산을 줄여 실시간 스트리밍 중에도 지연 시간을 극도로 낮췄습니다.
실제 벤치마크 데이터는 이 모델의 성능을 뒷받침합니다. 인디펜던트 분석 기관인 아티피셜 애널리틱스에 따르면, 이 모델은 스트리밍 ASR 모델 중 지연 시간 측면에서 2 위를 기록했습니다.
음성 종료 후 최종 전사 결과가 나오기까지 0.07 초라는 놀라운 속도를 보여줍니다. 정확도와 속도라는 두 마리 토끼를 모두 잡은 셈입니다.
이 기술이 주목받는 또 다른 이유는 개발자의 접근성 때문입니다. 모델이 오픈 가중치 형태로 공개되어 있어 API 의존성 없이 직접 파인튜닝이 가능합니다.
특정 도메인이나 지역 방언에 맞춰 데이터를 보정하면 훨씬 더 정밀한 결과를 얻을 수 있습니다. 데이터 수집부터 훈련, 평가, 그리고 확장까지 전 과정을 유연하게 설계할 수 있는 환경이 조성된 것입니다.
앞으로 주목해야 할 점은 이 모델이 실제 산업 현장에 어떻게 적용될지입니다. 단순한 기술 시연을 넘어 의료, 법률, 고객 서비스 등 전문 분야에서의 활용도가 높아질 것입니다.
특히 소수 언어나 특정 억양을 가진 사용자들에게도 높은 정확도를 제공할 수 있다는 점은 글로벌 서비스의 장벽을 낮출 것입니다. 음성 인터페이스의 미래가 더 빠르고 정교하게 재정의되는 순간이 다가오고 있습니다.