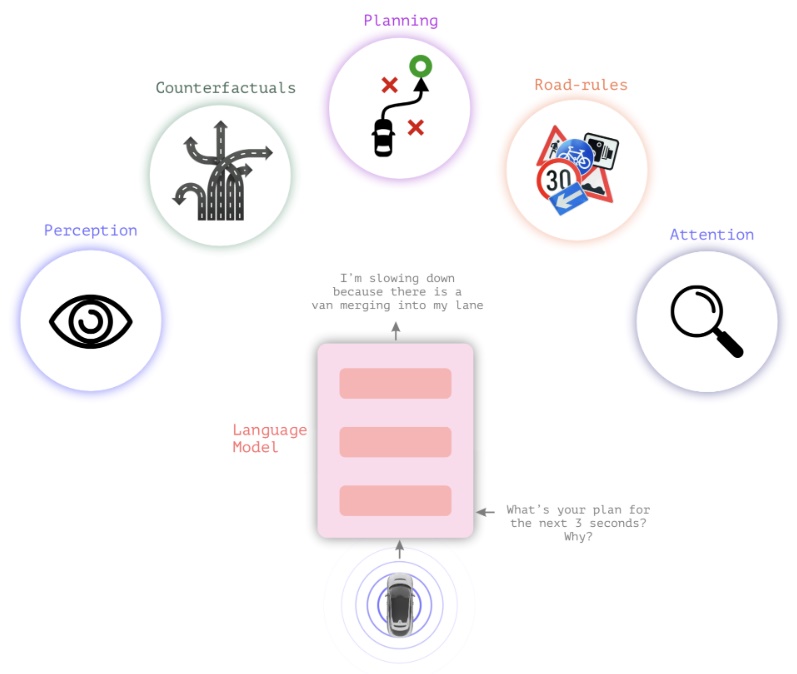
자율주행 기술의 최전선에서 가장 뜨거운 논쟁이 벌어지고 있습니다. 바로 언어 모델이 자율주행의 성능을 저하시킨다는 충격적인 주장입니다.
XPeng 의 자율주행 총괄 책임자 류선밍 박사는 최근 CVPR 2026 컨퍼런스에서 이 같은 파격적인 견해를 제시하며 업계의 이목을 집중시켰습니다. 그는 언어가 자율주행 시스템에 필수적인 중간 단계를 거쳐야 한다는 기존 상식을 깨뜨리며, 오히려 언어 처리 과정이 시스템의 반응 속도를 늦추고 오차를 유발한다고 설명했습니다.
이러한 주장은 XPeng 이 개발한 차세대 아키텍처인 VLA 2.0 에서 명확하게 드러납니다. 1 세대 모델이 도로 상황을 인식한 뒤 이를 언어적 표현으로 변환하고 다시 행동 명령으로 바꾸는 복잡한 과정을 거쳤다면, 2 세대 모델은 시각 정보를 직접 행동으로 연결하는 단계를 도입했습니다.
이 과정에서 언어라는 중간 매개체가 사라지면서 시스템의 판단 속도가 비약적으로 향상되었습니다. 류 박사는 이를 두고 언어가 자율주행의 흐름에 독이 된다고 표현하며, 불필요한 변환 과정이 제거된 것이 핵심 경쟁력이라고 강조했습니다.
실제 투자 규모와 기술 발전 속도를 보면 이 변화가 얼마나 급진적인지 알 수 있습니다. XPeng 은 매달 약 300 억 위안, 한화로는 약 4100 만 달러를 AI 학습에만 쏟아붓고 있습니다.
이 막대한 자원을 바탕으로 회사는 이미 테슬라의 FSD v13 과 동급의 성능을 달성했으며, 여름 전에는 v14 수준에 도달할 것으로 자신하고 있습니다. 이러한 기술적 도약은 단순한 소프트웨어 업데이트를 넘어, 자율주행 시스템이 어떻게 데이터를 처리하고 판단하는지에 대한 근본적인 재설계를 의미합니다.
업계 반응은 뜨겁습니다. 테슬라의 아쇼크 엘루스와미, 엔비디아, 웨이모의 리더들과 함께 무대를 공유한 류 박사의 발언은 단순한 기업 홍보를 넘어 산업 전체의 방향성을 제시하는 신호로 받아들여졌습니다.
특히 언어를 입력으로 받아 사용자의 명령을 이해하는 기능은 유지하되, 주행 중 실시간 판단 과정에서는 언어 토큰을 배제하는 전략은 효율성과 정확성을 동시에 잡은 해법으로 평가받고 있습니다. 이는 자율주행이 이제 언어적 추론보다는 시각적 직관에 더 의존해야 한다는 새로운 기준을 세웠습니다.
앞으로 주목해야 할 점은 이 기술이 실제 도로에서 어떻게 구현될지입니다. XPeng 의 VLA 2.0 아키텍처가 상용화되면 자율주행 차량의 반응 속도와 안전성 기준이 다시 한번 높아질 가능성이 큽니다.
특히 복잡한 도시 환경이나 갑작스러운 장애물 회피 상황에서 언어 처리의 부재가 얼마나 큰 차이를 만들지 지켜보는 것이 중요합니다. 자율주행 기술이 언어의 장벽을 넘고 순수한 시각 데이터로만 움직이는 시대가 열리면, 운전자의 경험은 완전히 달라질 것입니다.