하드디스크의 용량 걱정 없이 데이터를 저장할 수 있다면 어떨까요. 최근 글로벌 개발자 커뮤니티에서 이 같은 상상을 현실로 구현한 πFS가 다시 화제를 모으고 있습니다.
수학적 상수인 파이 속에 모든 데이터가 숨어있다는 전제에서 출발한 이 파일시스템은 단순한 호기심을 넘어 정보 이론의 한계를 다시 한번 생각하게 만듭니다.
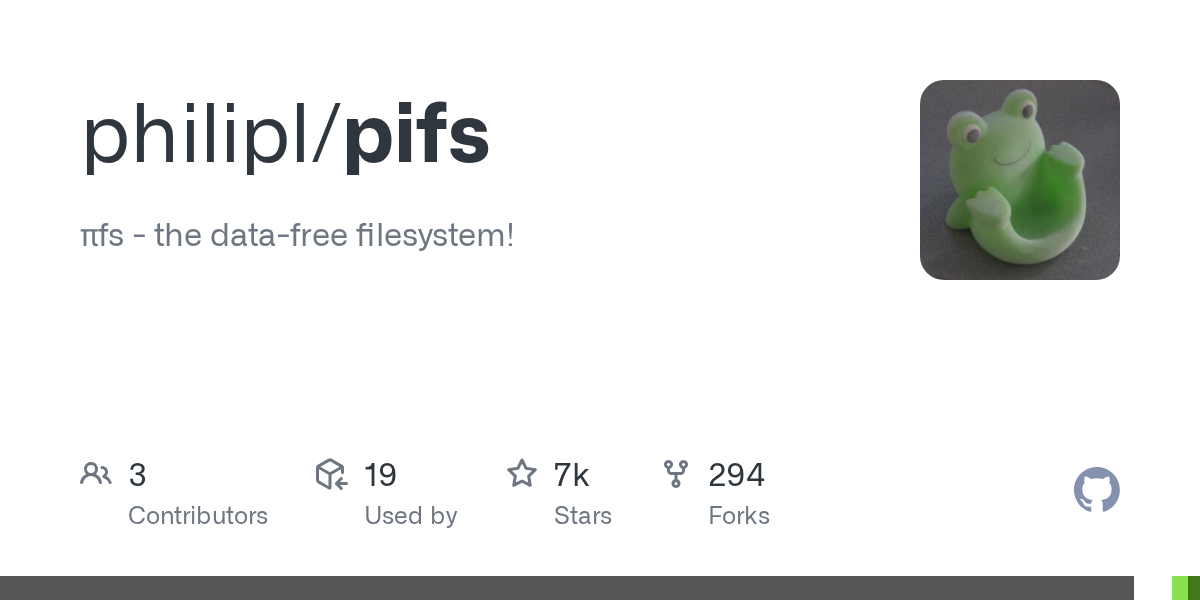
이 프로젝트가 다시 주목받는 직접적인 계기는 깃허브에서 공개된 코드와 해커뉴스에서의 활발한 논의입니다. 개발자 필립 리가 만든 오픈소스 프로젝트는 파이의 무한한 소수점 자릿수 속에 사용자의 파일을 인코딩하여 저장한다는 개념을 담고 있습니다.
데이터 자체를 물리적으로 저장하는 대신, 해당 데이터가 파이에 나타나는 위치와 길이를 기록하는 방식입니다.
하지만 기술적 효율성보다는 철학적 함의가 더 큰 관심을 끄는 이유입니다. 해커뉴스 사용자들은 이 아이디어를 과거의 ‘바벨의 도서관’ 개념과 비교하며 정보 이론의 본질을 되새기고 있습니다.
데이터를 압축하기 위해 필요한 주소 정보의 크기가 실제 데이터 크기와 비슷해지기 때문에, 이론적으로는 압축 효율이 낮을 수밖에 없다는 지적이 지배적입니다.
흥미로운 점은 현대의 대형 언어 모델이 이 고전적인 아이디어를 어떻게 재해석하고 있는지입니다. 많은 전문가들은 LLM이 손실 압축을 통해 데이터의 핵심 의미를 추출하는 방식이 πFS가 꿈꾸던 방향과 닮았다고 봅니다.
비록 완벽한 복원은 어렵지만, 거대한 기반 위에서 데이터의 본질을 압축한다는 점에서 유사한 논리가 작동한다는 분석입니다.
이러한 흐름은 단순한 기술적 유희를 넘어 데이터 저장의 패러다임 변화를 예고합니다. 물리적 저장 공간의 한계를 넘어서는 새로운 접근법이 등장할 때, 우리는 데이터의 본질이 무엇인지 다시 묻게 됩니다.
πFS가 제시한 무한한 수열 속 저장 개념은 앞으로 AI 기반의 압축 기술이 어떻게 발전할지에 대한 중요한 시사점을 던져줍니다.