데이터가 폭발적으로 늘어나는 요즘, 저장소 비용은 단순한 지출을 넘어 운영의 성패를 가르는 핵심 변수가 되었습니다. 특히 IoT 센서나 금융 시계열 데이터를 다루는 환경에서는 데이터 양이 기하급수적으로 증가해 기존 방식으로는 감당하기 어려운 부담이 생깁니다.
이런 상황에서 타임스케일DB가 기존 관계형 데이터베이스와는 차원이 다른 압축 기술을 선보이며 기술계의 이목을 집중시키고 있습니다.
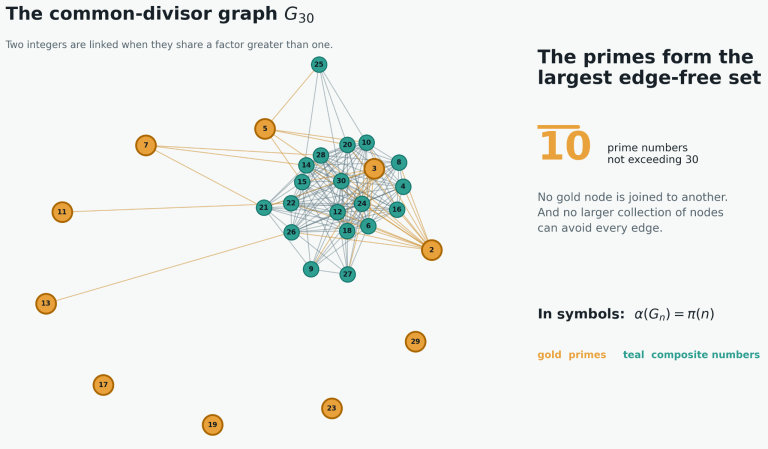
기존의 포스트그레SQL이 사용하는 TOAST 방식은 개별적으로 큰 값을 처리하는 데 특화되어 있지만, 시계열 데이터 특유의 패턴을 활용하지는 못했습니다. 타임스케일DB는 하이퍼코어 엔진을 통해 행 단위 저장을 열 단위 저장으로 전환하며 근본적인 접근법을 바꿨습니다.
이 방식은 데이터의 특성에 따라 델타 인코딩이나 고릴라 XOR 같은 전용 알고리즘을 적용해 불필요한 비트를 과감히 제거합니다.
실제 센서가 10 초마다 일정한 간격으로 데이터를 전송할 때, 시간 간격의 변화량만 저장하면 대부분의 데이터가 거의 제로에 가깝게 압축됩니다. 온도가 20.1 도에서 20.3 도처럼 서서히 변하는 부동소수점 값도 전체 8 바이트 대신 몇 비트만으로 표현이 가능해집니다.
저카디널리티를 가진 상태 코드나 장치 유형 같은 반복되는 값은 사전 인코딩을 통해 참조 번호로 치환되며, 최종적으로 LZ 압축이 더해져 압축 효율을 극대화합니다.
이러한 기술적 변화는 단순한 저장 공간 확보를 넘어 쿼리 성능에도 긍정적인 영향을 미칩니다. 압축된 데이터를 읽을 때 디코딩 오차가 발생하더라도, 필터링 단계에서 불필요한 스캔을 줄여 전체 처리 속도를 높일 수 있습니다.
특히 사전 인코딩을 통해 문자열 비교를 정수 비교로 변환하면 복잡한 조건문에서도 빠른 응답을 기대할 수 있어 분석 작업의 효율성이 크게 개선됩니다.
이제 데이터 아카이빙이나 파티셔닝으로 시간을 벌던 시기는 저물고, 모든 데이터를 온라인 상태에서 압축된 채로 실시간으로 조회하는 시대가 열렸습니다. 저장 비용 부담을 줄이면서도 데이터의 가치를 즉각적으로 활용하려는 기업들의 움직임이 활발해지고 있습니다.
향후 시계열 데이터를 다루는 모든 시스템이 이 같은 열 기반 압축 전략을 표준으로 받아들이게 될지, 그리고 그 한계가 어디까지 확장될지 지켜볼 필요가 있습니다.