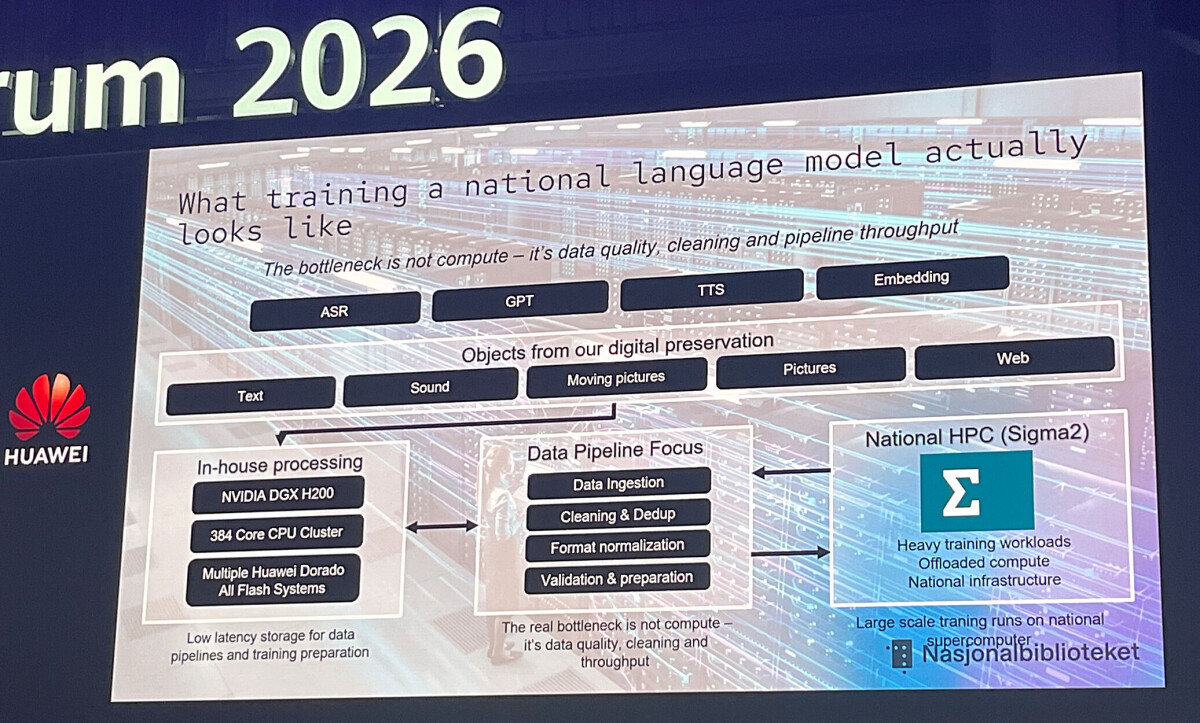
전 세계 AI 산업이 거대 기업들의 영어 기반 모델 경쟁으로 치닫는 와중, 노르웨이 국립도서관이 주목할 만한 움직임을 보였습니다. 도서관은 자국 언어로 훈련된 주권형 거대 언어 모델을 개발하기 위해 2페타바이트 규모의 화웨이 오션스토어 플래시 스토리지를 도입해 데이터 파이프라인을 구축했습니다. 이는 단순한 하드웨어 도입을 넘어, 영어 중심의 글로벌 모델이 놓칠 수밖에 없는 노르웨이의 역사, 뉴스, 문화를 온전히 이해하는 AI를 만들어내려는 의지의 표현입니다. 문화부가 도서관에 부여한 임무는 국가적 차원의 디지털 자산을 활용해 자국 언어에 최적화된 AI를 완성하는 것이었으며, 이는 상업적 기업들이 쉽게 따라오기 어려운 독보적인 영역입니다.
이 프로젝트가 주목받는 핵심 이유는 도서관이 보유한 방대한 데이터의 질과 양에 있습니다. 2005 년부터 이어온 디지털화 작업을 통해 노르웨이 전역의 출판물, 신문, 웹 페이지, 방송 콘텐츠 등을 수집해 20 페타바이트의 고유 데이터를 확보했습니다. 이 데이터는 3-2-1 백업 전략에 따라 총 60 페타바이트 규모로 안전하게 보관되고 있으며, 저작권이 있는 신문 자료까지 학습에 활용할 수 있는 법적 권한을 갖추고 있습니다. 상업적 기업들이 저작권 장벽에 부딪혀 제한된 데이터로 학습하는 것과 달리, 국가는 법적으로 보장된 수집 권한을 바탕으로 더 풍부하고 정확한 언어 모델을 훈련할 수 있는 환경을 마련한 것입니다.
하지만 기술 커뮤니티에서는 이 프로젝트의 실현 가능성에 대해 다양한 시각을 제시하기도 합니다. 448 개의 GPU 와 6 만 4 천 개 이상의 CPU 코어를 갖춘 슈퍼컴퓨터를 사용한다고는 하나, 전 세계적 규모의 모델을 처음부터 훈련하기에는 하드웨어 자원이 부족하다는 지적이 있습니다. 일부 전문가들은 완전한 모델을 훈련하기보다는 오픈 소스 모델을 기반으로 한 미세 조정 방식을 택하는 것이 더 현실적일 수 있다고 보며, 막대한 예산을 투입해 만든 모델이 실제로 유용한 수준으로 완성될지에 대한 의문을 제기합니다. 이러한 논의는 소수 언어권 국가가 AI 주권을 확보하기 위해 어떤 기술적 타협점을 찾아야 하는지에 대한 중요한 질문을 던집니다.
노르웨이의 시도는 앞으로 다른 소수 언어권 국가들에게도 중요한 참고 사례가 될 것입니다. 영어 중심의 AI 가 지배하는 환경에서 자국 문화의 뉘앙스를 잃지 않으려면, 단순히 번역된 데이터를 학습하는 것을 넘어 해당 언어로 쓰인 원천 자료로 직접 훈련된 모델이 필요하다는 인식이 확산되고 있기 때문입니다. 이제 중요한 것은 이 프로젝트가 단순한 실험을 넘어 실제 노르웨이 사회의 언어 생활에 어떻게 녹아들 것인지, 그리고 다른 국가들이 비슷한 주권 AI 전략을 펼칠 때 어떤 기술적, 재정적 모델을 따라갈 것인지입니다. 문화적 정체성을 디지털 시대에 어떻게 보존할 것인가에 대한 답이 이 작은 북유럽 국가의 시도에서 시작될지도 모릅니다.