최근 AI 기술계의 화두는 더 이상 텍스트와 이미지의 결합을 넘어선 ‘올모달’ 시대로의 전환입니다. 엔비디아가 공개한 네모트론 3 나노 오미는 이러한 흐름을 주도하는 핵심 모델로, 문서 분석, 오디오 처리, 비디오 이해를 하나의 아키텍처에서 통합적으로 수행할 수 있는 능력을 갖췄다는 점에서 주목받고 있습니다. 기존에 분리되어 있던 비전 언어 시스템이 텍스트, 이미지, 비디오, 오디오를 모두 아우르는 범용 모델로 진화한 것입니다.
이 모델이 주목받는 가장 큰 이유는 실용성과 효율성의 극대화입니다. 복잡한 문서 지능 평가 지표인 MMlongbench-Doc 과 OCRBenchV2 에서 최상위권의 정확도를 기록한 것은 물론, 영상 및 오디오 분야인 WorldSense 와 DailyOmni 에서도 선두를 달리고 있습니다. 특히 음성 이해 능력은 VoiceBench 에서 최상위권을 차지했으며, 오픈형 비디오 이해 모델 중에서는 비용 대비 효율성이 가장 뛰어난 것으로 평가받았습니다. 이는 단순한 성능 향상을 넘어 실제 비즈니스 환경에서 대규모 데이터를 처리할 때 발생하는 비용과 시간 문제를 해결할 수 있음을 시사합니다.
기술적 배경을 살펴보면, 네모트론 3 하이브리드 Mamba-Transformer 혼합 전문가 구조에 C-RADIOv4-H 비전 인코더와 Parakeet-TDT-0.6B-v2 오디오 인코더가 결합된 점이 핵심입니다. 이 설계는 미세한 시각적 세부 사항을 보존하면서도 네이티브 오디오 이해 능력을 추가하고, 밀집된 이미지나 긴 문서, 비디오와 같은 긴 멀티모달 컨텍스트로 확장할 수 있도록 최적화되었습니다. 학습 과정에서는 단계적 멀티모달 정렬과 컨텍스트 확장을 거친 후 선호도 최적화와 멀티모달 강화 학습을 적용하여 성능을 끌어올렸습니다.
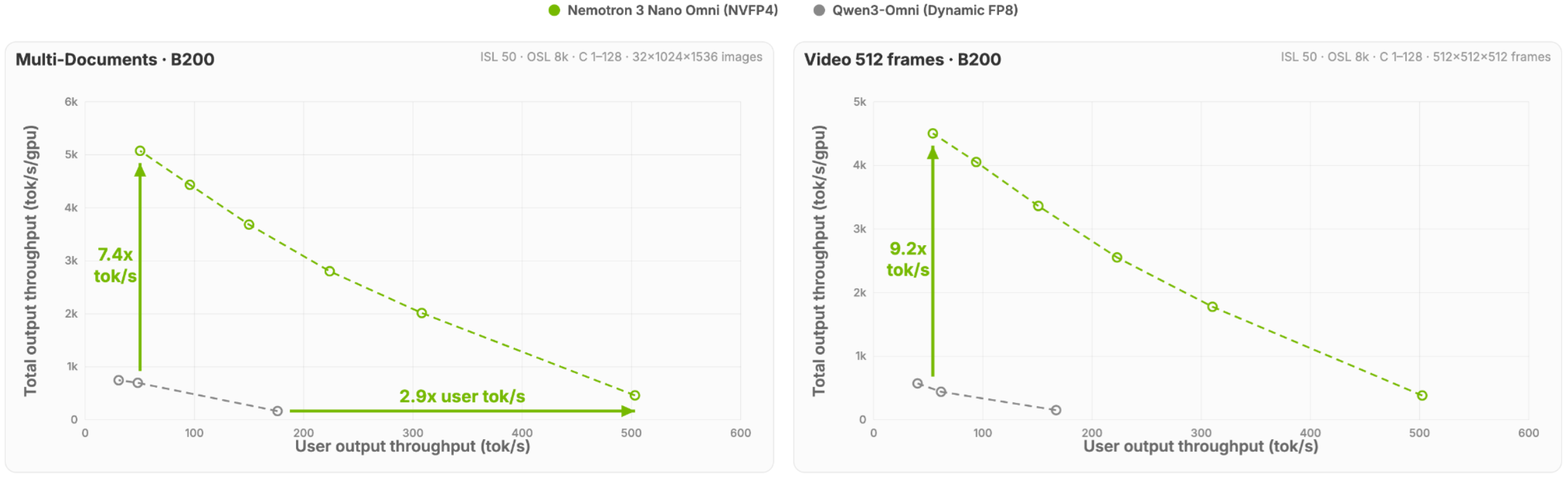
결과적으로 이 모델은 멀티모달 사용 사례에서 기존 대안 대비 최대 9 배 높은 처리량과 2.9 배의 단일 스트림 추론 속도를 달성했습니다. BF16, FP8, NVFP4 체크포인트가 허깅페이스를 통해 공개됨에 따라 개발자들은 다양한 환경에 맞춰 모델을 활용할 수 있게 되었습니다. 앞으로는 단순한 인식 단계를 넘어 에이전트가 컴퓨터를 직접 조작하거나 복잡한 추론을 수행하는 단계로 AI 의 역할이 확장될 것으로 예상됩니다. 네모트론 3 나노 오미는 이러한 변화의 시작점을 알리는 강력한 신호탄이 될 것입니다.






