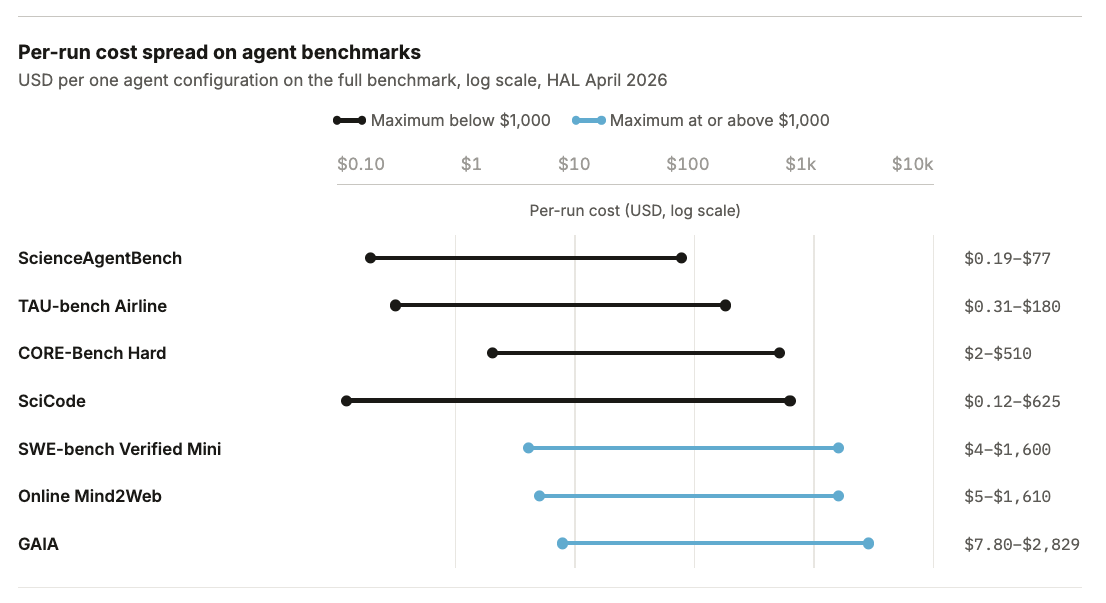
인공지능 산업의 초점이 단순한 모델 훈련에서 실제 환경에서의 에이전트 행동으로 이동하면서, 평가 과정의 비용 구조가 근본적으로 변하고 있습니다. 과거에는 모델의 정확도를 검증하는 것이 상대적으로 저렴하거나 간과되던 단계였다면, 이제는 평가 자체가 가장 큰 컴퓨팅 병목 현상을 일으키는 핵심 변수로 부상했습니다. 특히 에이전트 기반 벤치마크가 등장하면서 동일한 작업이라도 사용하는 스캐폴드 구조에 따라 비용 차이가 33 배까지 벌어지는 현상이 관찰되고 있습니다. 이는 단순히 모델의 성능을 비교하는 것을 넘어, 어떤 아키텍처로 평가 환경을 구성하느냐에 따라 전체 프로젝트의 경제성이 결정될 수 있음을 시사합니다.
실제 사례를 보면 이러한 비용 상승 추세가 더욱 명확해집니다. 홀리스틱 에이전트 리더보드 프로젝트는 9 개의 모델과 9 개의 벤치마크를 대상으로 2 만 건 이상의 에이전트 롤아웃을 수행하는 데 약 4 만 달러의 비용이 소요되었습니다. 또한 최첨단 모델을 대상으로 한 단일 GAIA 실행만으로도 캐싱 전 기준 2,800 달러가 넘는 비용이 발생하며, 과학적 머신러닝 분야에서 새로운 아키텍처 하나를 평가하는 데 수백 시간에서 수천 시간의 H100 GPU 시간이 투입되기도 합니다. 이러한 수치는 평가 과정이 더 이상 가볍게 지나갈 수 있는 단계가 아님을 보여줍니다.
이러한 비용 폭발의 배경에는 평가의 복잡성과 신뢰성 확보를 위한 반복 실행이 자리 잡고 있습니다. 정적 벤치마크를 위한 압축 기술이 제안되었지만, 에이전트 벤치마크는 노이즈가 많고 구성 요소에 민감하여 완전히 압축하기 어렵습니다. 특히 훈련 과정에 평가 루프를 포함시키거나 신뢰도를 높이기 위해 반복 실행을 추가할 경우 비용은 기하급수적으로 증가합니다. 2022 년 스탠포드 연구진이 발표한 HELM 보고서에서도 이미 모델당 API 비용이 85 달러에서 1 만 달러 이상까지 편차가 크다는 사실이 드러났으며, 전체 30 개 모델과 42 개 시나리오를 아우르는 평가에는 약 10 만 달러의 총비용이 들었습니다.
앞으로 AI 산업에서 중요한 것은 단순히 더 강력한 모델을 만드는 것이 아니라, 얼마나 효율적으로 그 모델을 검증할 것인가를 설계하는 것입니다. 개발 단계에서 수많은 체크포인트를 반복 평가해야 하는 현실을 고려할 때, 평가 비용의 최적화는 곧 모델 개발 속도와 직결됩니다. 이제 기업과 연구진은 평가 인프라의 확장성과 비용 효율성을 전략적 우선순위로 삼아야 하며, 평가 과정 자체를 혁신하는 새로운 기술과 아키텍처가 시장의 다음 흐름을 이끌 것으로 예상됩니다.