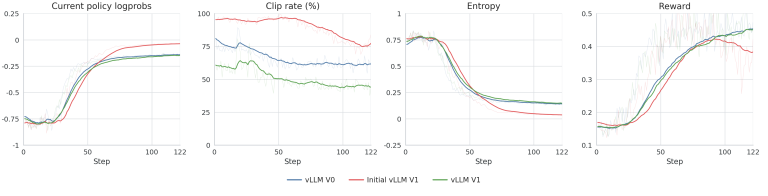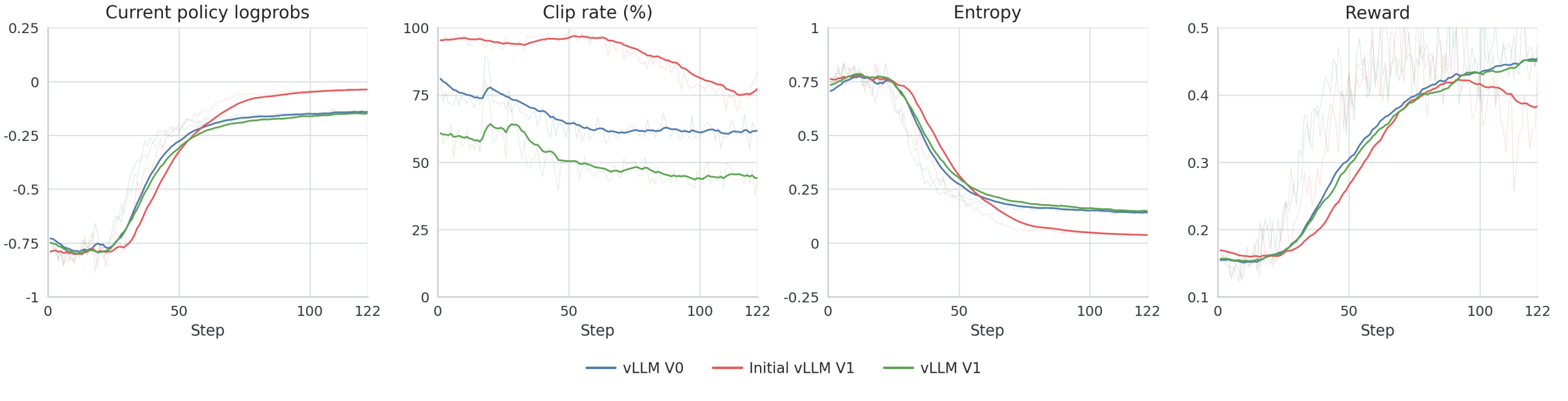
강화학습 분야에서 최근 가장 뜨거운 감자는 추론 엔진의 버전 변경이 학습 결과에 미치는 파급력입니다. 특히 vLLM V0 에서 V1 로 넘어가는 과정에서 발생한 ‘정확성 우선’ 접근 방식이 주목받고 있는데, 이는 단순히 성능 향상을 넘어 학습의 근본적인 안정성을 확보하려는 시도에서 비롯되었습니다. ServiceNow-AI 가 Hugging Face 블로그를 통해 공개한 사례는 vLLM 이 강화학습의 추론 엔진으로 사용될 때, 토큰 샘플링과 로그확률 반환 방식의 미세한 불일치가 전체 학습 동역학을 어떻게 뒤흔드는지를 명확하게 보여줍니다. 많은 개발자가 새로운 버전의 도입을 성능 개선의 기회로만 생각하지만, 실제 강화학습 파이프라인에서는 추론 단계에서 나오는 데이터의 형식이 학습기의 기대와 일치하지 않으면 수렴 자체가 불가능해질 수 있다는 점이 핵심입니다.
이러한 문제가 대두된 직접적인 계기는 vLLM V1 엔진이 V0 대비 대대적인 리팩토링을 거치면서 발생했습니다. 초기 V1 환경에서 실행된 학습은 V0 기준 참조값과 비교해 학습 초반부터 보상과 로그확률 값이 급격히 이탈하는 현상을 보였습니다. 이는 처리된 롤아웃 로그확률의 계산 방식, V1 고유의 런타임 기본값 설정, 비행 중 가중치 업데이트 경로, 그리고 최종 프로젝션에 사용된 fp32 lm_head 의 차이에서 기인했습니다. 특히 온라인 강화학습 시스템이 롤아웃 측의 로그확률을 최적화 목표의 일부로 삼는 PPO 나 GRPO 같은 알고리즘에서는 이러한 불일치가 학습의 방향성을 완전히 왜곡시킬 수 있어, 백엔드 행동을 먼저 고정하지 않고는 새로운 목적 함수를 적용하는 것이 위험하다는 판단이 내려졌습니다.
문제를 해결하기 위해 ServiceNow-AI 는 학습 목표의 변경보다 먼저 백엔드의 정확성을 회복하는 데 집중했습니다. vLLM 0.8.5 를 기준으로 한 V0 참조 실행과 vLLM 0.18.1 을 사용한 V1 실행을 비교했을 때, 네 가지 주요 수정 사항을 적용한 후야 비로소 V1 이 V0 의 참조값과 일치하는 결과를 내놓았습니다. 이 과정은 단순히 버그를 수정하는 것을 넘어, 강화학습 시스템이 추론 엔진의 내부 로직 변화에 얼마나 민감하게 반응하는지를 보여주는 실험이었습니다. 학습기 측면에서 계산된 로그확률과 보상이 초기 단계에서 참조값과 달라진다는 사실은, 알고리즘이 의도한 대로 정책을 업데이트하지 못하고 엉뚱한 방향으로 학습을 진행할 수 있음을 의미합니다.
이제 주목해야 할 점은 이러한 백엔드 정확성 확보가 향후 어떤 변화를 예고하느냐는 것입니다. vLLM V1 의 성공적인 마이그레이션은 강화학습 파이프라인 설계 시 추론 엔진의 버전 관리가 단순한 인프라 업데이트가 아니라 학습 전략의 일부로 다뤄져야 함을 시사합니다. 앞으로는 다양한 강화학습 모델이 vLLM V1 기반으로 전환되면서, 로그확률의 시맨틱과 런타임 디폴트 값에 대한 표준화가 더욱 중요해질 것입니다. 특히 대규모 언어 모델을 활용한 온라인 학습 시스템에서는 추론 단계의 일관성이 곧 학습의 성패를 가르는 핵심 변수가 되므로, 엔진 업데이트 시에는 반드시 학습 동역학의 불변성을 검증하는 절차가 선행되어야 할 것입니다.