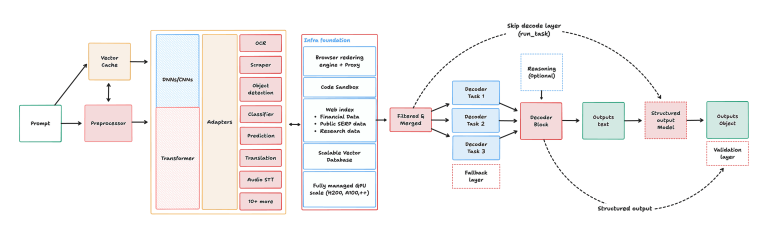
오랫동안 인공지능 모델의 성능 향상은 단순히 더 많은 연산 자원을 투입하는 것, 즉 ‘규모의 확장’과 직결되어 있었습니다. 파라미터 수와 학습 데이터, 그리고 사용된 연산량을 늘리면 손실 함수가 예측 가능한 법칙에 따라 줄어든다는 경험적 연구들이 이를 뒷받침해 왔습니다. 하지만 최근 AI 업계의 흐름은 이 단순한 곡선을 넘어섰습니다. 이제는 사전 학습 단계뿐만 아니라, 모델의 성향을 맞추는 미세 조정이나 강화 학습 같은 사후 학습 과정, 그리고 실제 사용자가 질문을 던졌을 때 답을 찾아내는 추론 단계까지 전체 수명 주기를 아우르는 통합적인 접근이 필수적이 되었습니다.
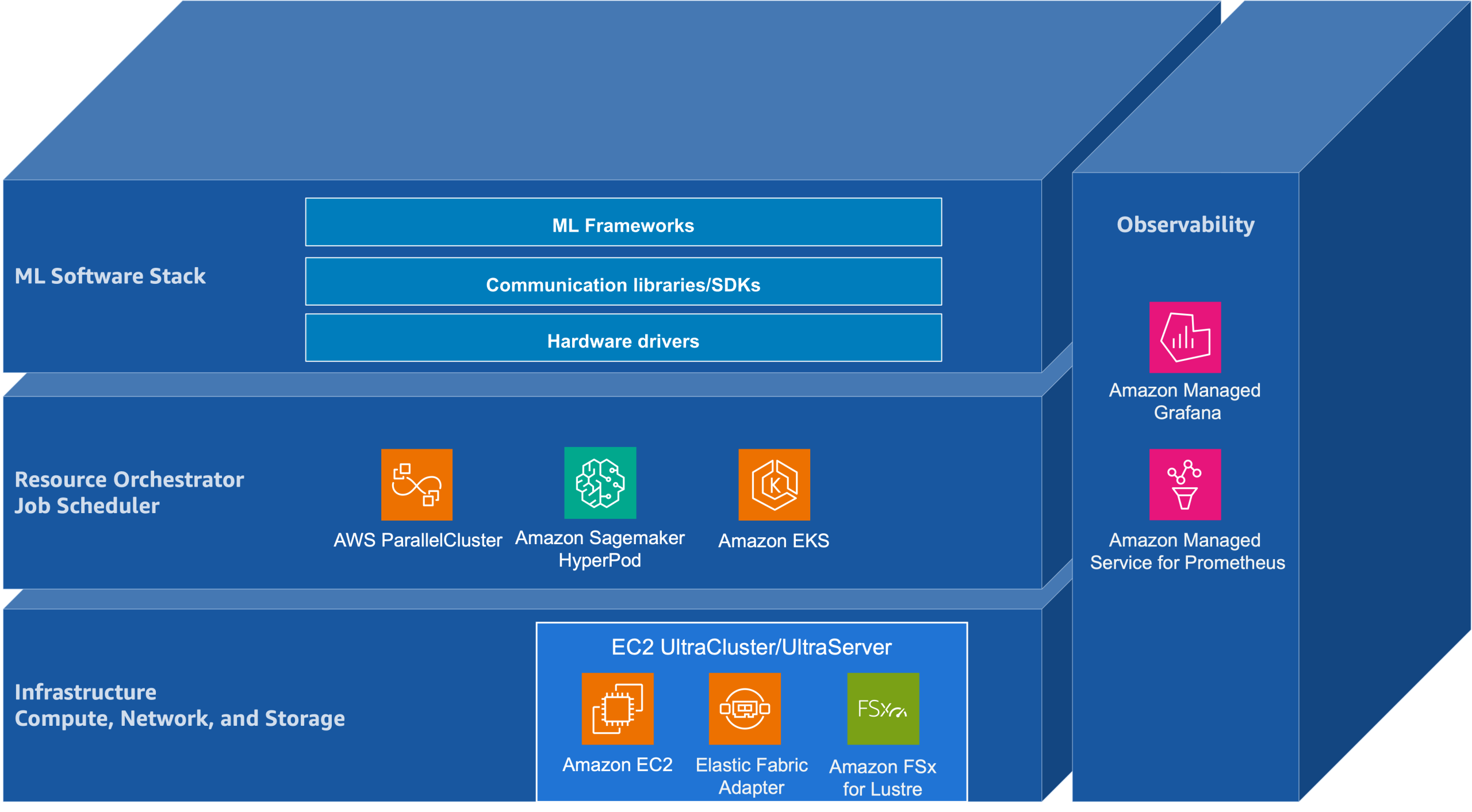
이러한 변화는 인프라 요구 사항에도 큰 영향을 미쳤습니다. 단순히 고성능 가속기만 무작정 늘리는 방식으로는 한계가 명확해졌기 때문입니다. 최신 트렌드는 가속기 연산, 대역폭이 넓고 지연 시간이 짧은 네트워크, 그리고 분산형 저장소 백엔드가 긴밀하게 결합된 환경을 강조합니다. 특히 대규모 클러스터에서 자원을 효율적으로 관리하기 위한 오케스트레이션 도구와, 하드웨어부터 애플리케이션 수준까지 시스템의 건강 상태를 실시간으로 파악할 수 있는 가시성 확보가 성패를 가르는 중요한 변수로 부상했습니다.
또한 이 모든 과정을 뒷받침하는 것은 오픈 소스 소프트웨어 생태계의 역할입니다. 모델 개발 프레임워크부터 클러스터 자원 관리에 이르기까지 다양한 오픈 소스 도구들이 서로 유기적으로 연결되어야만 복잡한 AI 워크로드를 원활하게 소화할 수 있습니다. 이는 마치 고층 건물을 지을 때 튼튼한 기둥뿐만 아니라 전기 배선, 수도관, 그리고 공기 순환 시스템이 완벽하게 조화를 이루어야 하는 것과 같은 이치입니다. 각 요소가 따로 놀면 아무리 강력한 컴퓨팅 파워를 갖춰도 전체 시스템의 효율은 떨어지게 마련입니다.
앞으로 주목해야 할 점은 이러한 인프라 통합이 AI 개발의 진입 장벽을 낮추고 혁신 속도를 높일 것이라는 점입니다. 기업과 개발자들은 이제 개별적인 하드웨어 성능보다는 전체 파이프라인이 얼마나 매끄럽게 연동되는지에 더 집중하게 될 것입니다. 단순한 확장 논리에서 벗어나 모델의 전 생애 주기를 고려한 인프라 설계가 가능해지면, 더 정교하고 효율적인 AI 서비스를 만드는 데 필요한 시간과 비용도 크게 절감될 수 있습니다. 이는 AI 기술이 거대 기업만의 전유물이 아닌, 더 넓은 범위의 혁신 주체들에게도 실질적인 기회를 열어주는 전환점이 될 것입니다.