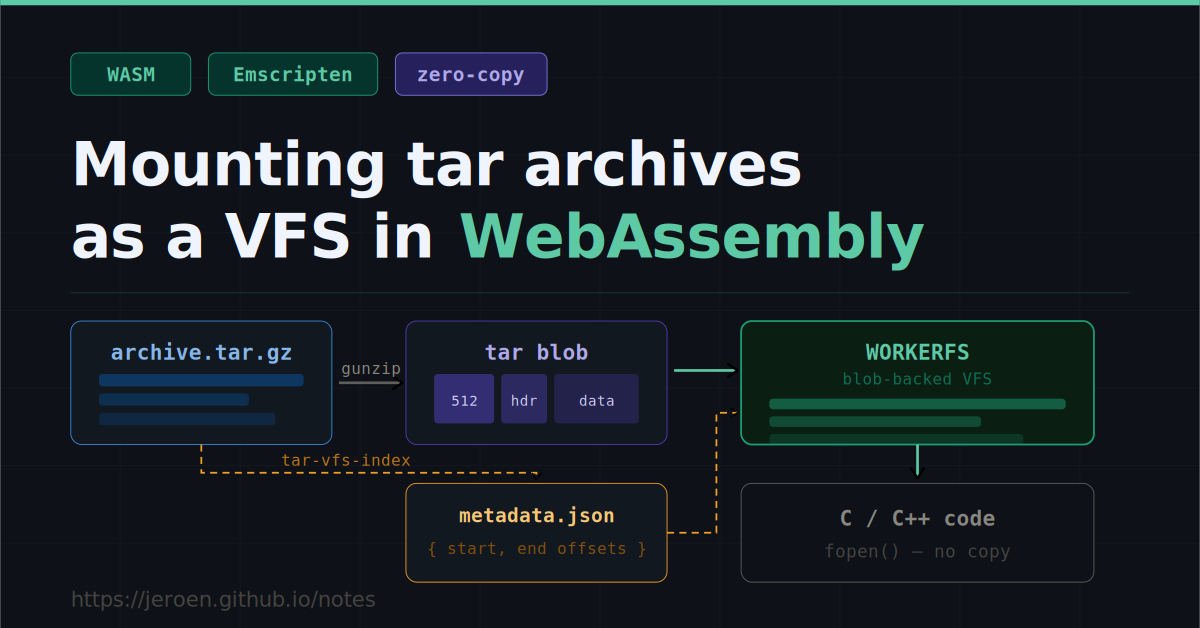
웹 브라우저에서 대용량 데이터를 다룰 때 가장 골치 아픈 순간 중 하나는 압축된 tar.gz 파일을 모두 풀어서 메모리에 올려야 한다는 점입니다. 예전에는 전체 파일을 다운로드하고 압축을 해제한 뒤 필요한 파일만 추출하는 과정이 필수였는데, 이 과정에서 메모리 부족이나 느린 로딩 속도가 빈번하게 발생했습니다. 하지만 최근 웹어셈블리 환경에서 이 문제를 우아하게 해결한 기술이 주목받으며 개발자들 사이에서 화제가 되고 있습니다.
핵심은 전체 파일을 풀지 않고도 특정 파일에 접근할 수 있게 하는 ‘인덱스’를 활용하는 것입니다. tar 아카이브 내부에 각 파일의 크기와 위치를 기록한 작은 메타데이터 파일을 생성해 두면, 웹어셈블리 가상 파일시스템이 이 정보를 바탕으로 압축된 덩어리 안에서 필요한 부분만 바로 찾아낼 수 있습니다. 마치 도서관에서 책 전체를 다 펼쳐보지 않고도 목차를 보고 원하는 페이지를 바로 찾아내는 것과 비슷합니다. 이 방식은 특히 메모리 제한이 엄격한 웹 환경에서 데이터 처리 효율을 극대화해 줍니다.
실제로 R 언어의 웹 버전인 WebR 이 이 기술을 도입하면서 큰 효과를 본 사례가 있습니다. 기존에는 R 패키지를 배포할 때 압축을 풀어야 했지만, 이제는 압축된 tar.gz 파일에 인덱스를 붙여 그대로 배포해도 웹 브라우저에서 즉시 실행할 수 있게 되었습니다. 결과적으로 서버에서는 기존 압축 파일 형식을 그대로 유지하면서도, 사용자는 훨씬 빠른 속도로 패키지를 로드할 수 있게 된 것입니다. Emscripten 같은 도구들이 제공하는 가상 파일시스템과 결합되면서 이 기술은 단순한 아이디어를 넘어 실제 개발 워크플로우에 적용 가능한 현실적인 솔루션으로 자리 잡았습니다.
물론 이 기술이 만능은 아닙니다. 압축된 상태의 tar.gz 파일 자체를 부분적으로 읽는 것보다는 인덱스를 통해 위치를 파악하는 방식이라, 여전히 전체 파일을 메모리에 로드해야 하는 한계가 있다는 지적도 있습니다. 하지만 전체를 풀어서 복사하는 과정보다는 메모리 사용량을 줄이고 접근 속도를 높이는 데는 확실히 유리합니다. 특히 대용량 데이터셋이나 복잡한 라이브러리를 웹 환경에서 다뤄야 하는 개발자들에게는 매우 반가운 변화입니다. 앞으로는 이 방식이 더 다양한 압축 포맷이나 파일 시스템 이미지에도 적용될지, 혹은 웹 환경에서의 데이터 처리 방식이 어떻게 진화할지 지켜보는 것이 흥미로울 것입니다.