최근 인공지능 분야에서 ‘크기만 크면 좋은 것’이라는 통념이 깨지고 있습니다. IBM 이 공개한 최신 모델인 그라나이트 4.1 이 화제가 된 이유는 바로 이 지점에서 시작됩니다. 과거에는 거대한 파라미터 수를 자랑하는 모델이 성능의 기준이었지만, 이제는 적은 자원으로 높은 효율을 내는 ‘작고 똑똑한’ 모델이 주목받고 있기 때문입니다.
그라나이트 4.1 이 주목받는 첫 번째 이유는 학습 데이터의 정제 과정에 있습니다. 단순히 방대한 양의 데이터를 한 번에 학습시키는 것이 아니라, 일반 데이터에서 시작해 수학 및 코딩 데이터로, 다시 고품질 데이터로 정제하는 5 단계를 거치는 다단계 전처리 방식을 채택했습니다. 특히 15 조 개의 토큰을 학습시키면서도 데이터의 질을 최우선으로 삼아, 불필요한 노이즈를 제거하고 핵심 정보만 선별해 넣는 과정을 거쳤습니다. 이는 마치 요리할 때 재료를 무작정 많이 넣는 것이 아니라, 가장 신선하고 적합한 재료만 골라 요리의 맛을 극대화하는 것과 같은 원리입니다.
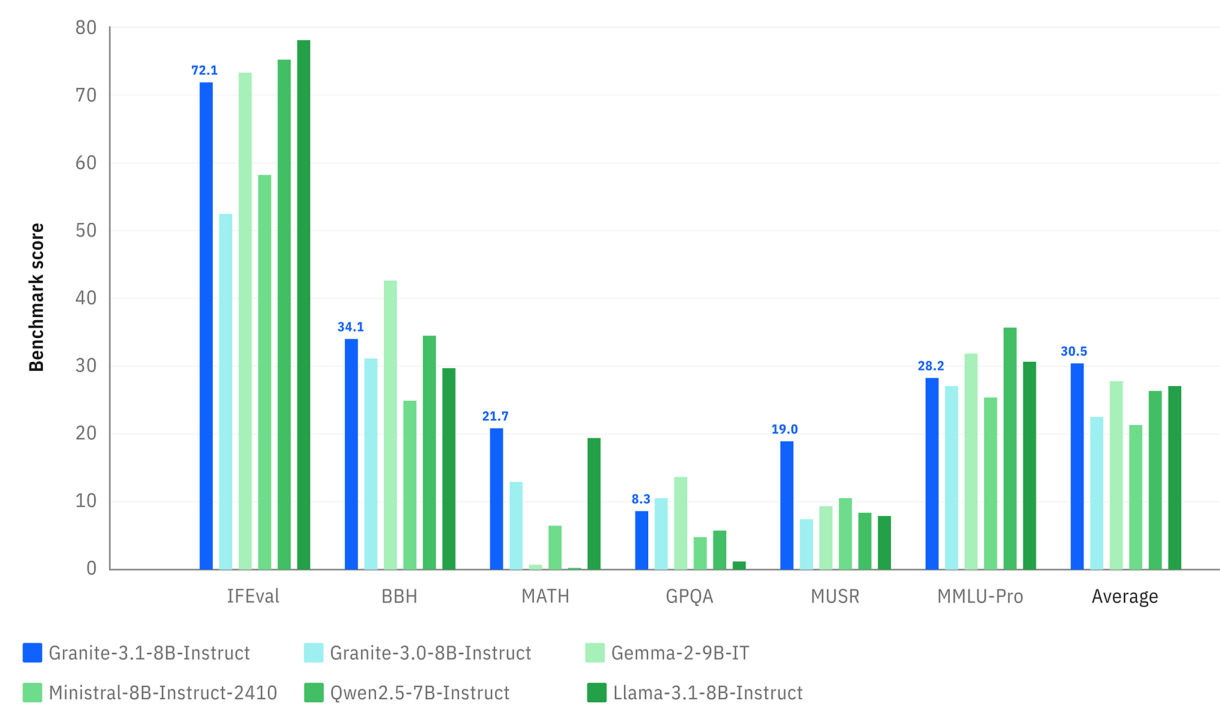
두 번째로 눈여겨볼 점은 80 억 파라미터 모델이 320 억 파라미터 모델의 성능을 따라잡거나 능가한다는 사실입니다. 이전 세대인 그라나이트 4.0-H-Small 은 320 억 파라미터의 희소 혼합 전문가 구조를 사용했지만, 4.1 의 80 억 모델은 더 단순한 밀집 구조임에도 불구하고 비슷한 성능을 보여줍니다. 이는 복잡한 구조를 유지하기 위해 많은 전산 자원을 소모하던 과거 방식에서 벗어나, 효율적인 아키텍처로 성능을 끌어올릴 수 있음을 증명하는 사례입니다.
세 번째 특징은 긴 문맥을 이해하는 능력입니다. 최대 512K 토큰까지의 긴 문맥을 처리할 수 있도록 훈련을 확장했습니다. 이는 방대한 분량의 문서나 긴 대화 내용을 한 번에 파악하고 핵심을 요약하는 데 큰 도움을 줍니다. 실제로 수백 페이지에 달하는 기술 문서나 긴 대화 기록을 분석할 때, 이전 모델들이 놓치기 쉬운 연결 고리를 놓치지 않고 파악할 수 있게 된 것입니다.
마지막으로 이 모델들이 오픈소스 생태계에 미치는 영향입니다. 모든 그라나이트 4.1 모델은 아파치 2.0 라이선스로 공개되어 있어, 누구나 자유롭게 상업적 용도로 활용할 수 있습니다. 데이터 정제부터 강화 학습까지의 전 과정이 투명하게 공개되면서, 개발자들은 이 모델을 기반으로 자신만의 맞춤형 AI 를 쉽게 구축할 수 있게 되었습니다. 앞으로는 거대 모델의 압도적인 성능보다는, 특정 업무에 최적화되고 자원을 적게 쓰면서도 신뢰할 수 있는 작은 모델들이 일상생활과 비즈니스 현장에서 더 많이 쓰일 것으로 예상됩니다.






