클로드 코드를 사용하는 개발자들이 최근 가장 골머리를 앓는 지점은 세션이 끝난 후 남는 방대한 기록을 해석하는 데 있습니다. 한 번의 세션에서 생성되는 JSONL 파일은 수천 줄에 달하며, 에이전트가 왜 특정 프로덕션 환경을 건드렸는지 혹은 컨텍스트 예산이 어디로 소모되었는지를 파악하려면 이 긴 코드를 일일이 훑어야 합니다.
실무 현장에서는 이 파일이 사실상 쓰기 전용으로 방치되는 경우가 많습니다. 4,000 줄에 달하는 데이터를 펼쳐놓고 에이전트의 판단 근거를 찾기란 시간과 노력이 너무 많이 들기 때문입니다.
바로 이 지점에서 ‘헤르’라는 새로운 도구가 주목받기 시작했습니다.
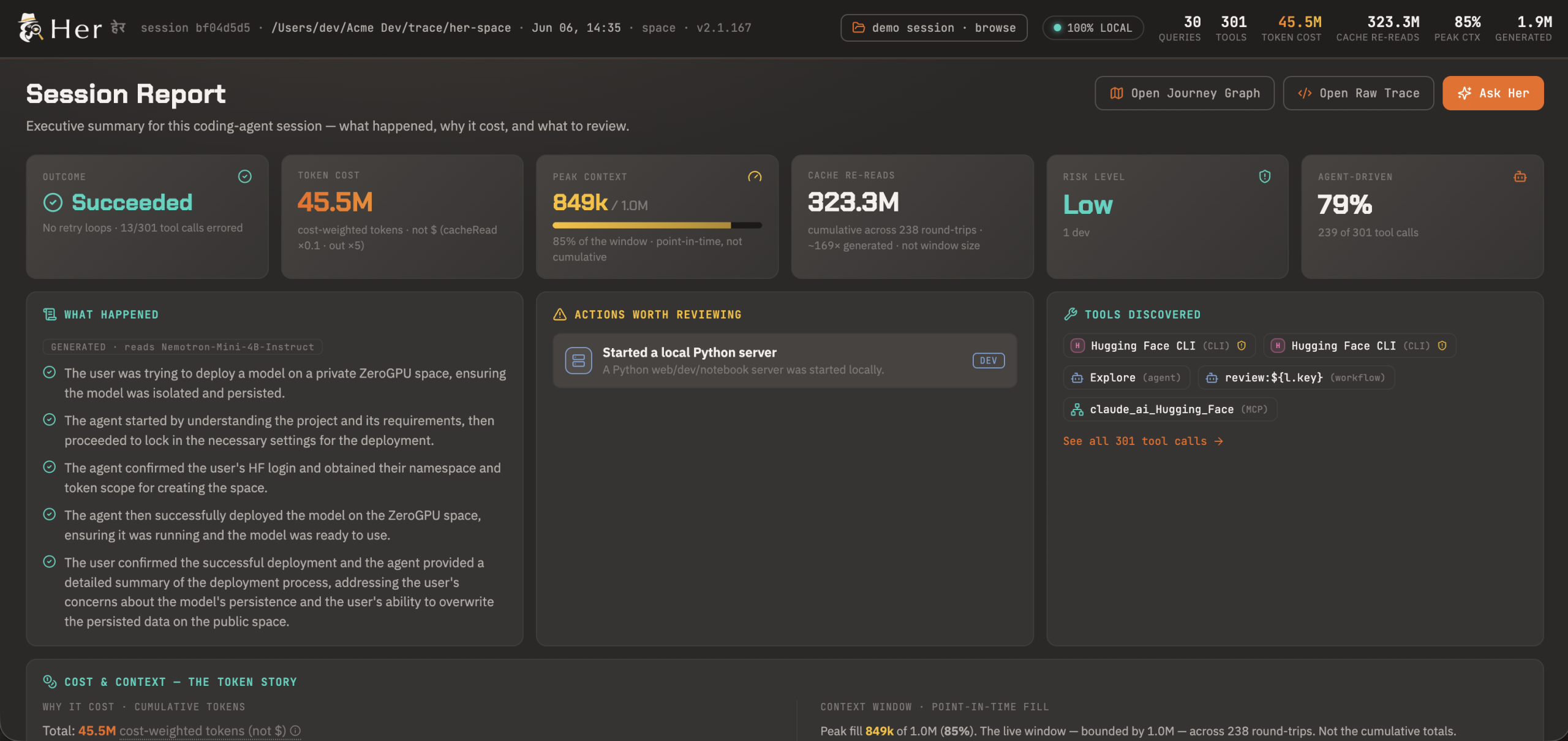
헤르는 세션 파일을 업로드하면 복잡한 기술적 흔적을 평이한 영어로 재구성해 줍니다. 배포나 설정 변경, 비밀 키 접근과 같은 위험한 행보를 자동으로 식별하고, 각 행위가 발생한 정확한 시점을 추적해 보여줍니다.
단순히 무언가를 주장하기보다는 제안하는 방식으로 작동하며, 개선이 필요한 패턴이 명확할 때만 구체적인 조언을 건넵니다.
이 도구의 가장 큰 강점은 외부 AI API 를 호출하지 않고 자체 GPU 에서 모델을 구동한다는 점입니다. 네모트론 미니 4B 인스트럭트 모델이 공간 내 GPU 를 통해 실행되며, 업로드된 세션 데이터는 사용자의 런에 속한 비공개 네임스페이스에 일시적으로 저장된 뒤 자동 삭제됩니다.
데이터가 외부로 유출되지 않는 구조라 신뢰도가 높습니다.
단일 세션뿐만 아니라 여러 파일을 한꺼번에 업로드하면 프로젝트 전체의 흐름을 분석할 수도 있습니다. 특정 질문을 던지면 헤르는 해당 답변을 근거로 들며 정확한 툴 호출을 열어 보여줍니다.
이제 개발자들은 복잡한 로그를 직접 파헤치는 수고를 덜고, 에이전트의 사고 과정을 직관적으로 이해하며 더 효율적인 코딩을 이어갈 수 있게 되었습니다.