인공지능 분야에서 가장 뜨거운 질문 중 하나는 대규모 언어 모델이 기존 하이퍼파라미터 최적화 알고리즘을 대체할 수 있느냐는 것입니다. 최근 발표된 연구 결과는 이 질문에 대해 명확한 답을 내놓았습니다.
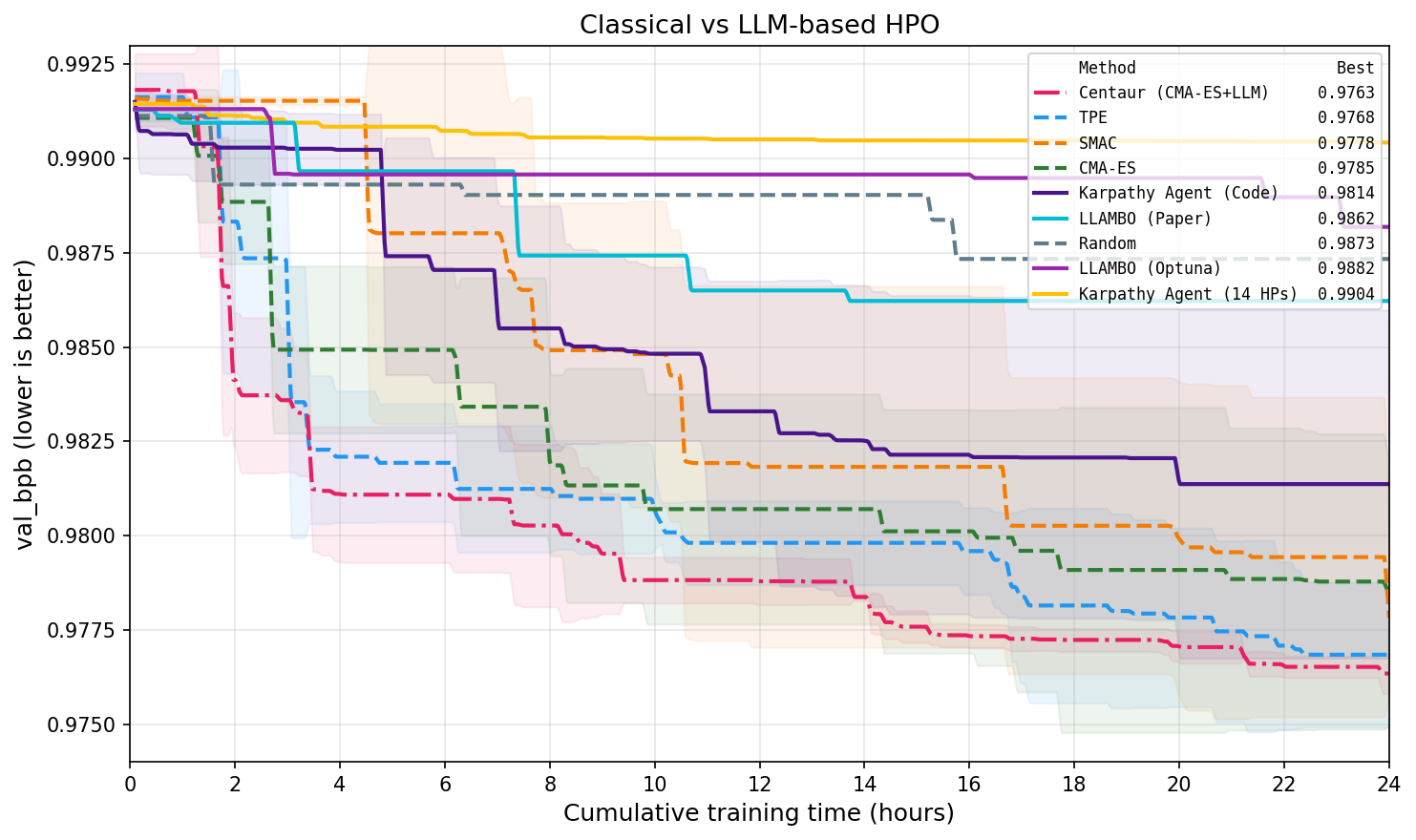
단순히 코드만 직접 수정하는 방식의 LLM 에이전트는 고정된 연산 예산 하에서 CMA-ES나 TPE 같은 전통적인 알고리즘보다 일관되게 낮은 성능을 보였습니다.
특히 메모리 부족으로 인한 실패를 피하는 것이 검색의 다양성보다 중요한 변수로 작용했습니다. 최첨단 모델이라 하더라도 최적화 상태를 여러 번의 시도 동안 일관되게 추적하는 데 어려움을 겪는 것으로 나타났습니다.
이는 모델의 규모가 커진다고 해서 무조건 성능이 비례하여 향상되는 것은 아님을 시사합니다.
하지만 LLM이 완전히 무능한 것은 아닙니다. 도메인 지식과 직관을 활용하는 능력에서 기존 알고리즘이 가진 한계를 보완할 수 있습니다.
연구진은 이 두 가지 강점을 결합한 혼종 모델인 센타우르를 제안했습니다. 이 모델은 CMA-ES의 해석 가능한 내부 상태를 LLM과 공유하며 협력합니다.
실험 결과, 센타우르는 순수 LLM 방식과 기존 알고리즘 모두를 능가하는 최상의 결과를 기록했습니다. 흥미롭게도 0.8B 규모의 작은 모델만으로도 모든 경쟁자를 이길 수 있었습니다.
반면 LLM이 코드를 자유롭게 수정하는 방식은 더 큰 모델이 필요했고, 여전히 기존 알고리즘에 미치지 못했습니다.
이러한 흐름은 향후 AI 개발 전략에 중요한 시사점을 줍니다. LLM을 단독 최적화 도구로 사용하기보다는 기존 최적화 루틴을 보조하는 역할로 활용하는 것이 효율적입니다.
특히 하이브리드 방식에서 LLM이 개입하는 비율을 적절히 조절하는 것이 성패를 가를 것입니다. 앞으로는 어떤 분야에서 LLM의 직관이 더 큰 효과를 발휘할지, 그리고 혼종 모델의 구체적인 적용 사례가 어떻게 확장될지 지켜볼 필요가 있습니다.