최근 음성 AI 에이전트가 이중언어 고객을 얼마나 자연스럽게 상대할 수 있는지에 대한 관심이 급증하고 있습니다. 단순히 한 가지 언어만 인식하는 것을 넘어, 대화 중간에 언어를 섞어 쓰는 코드스위칭까지 처리할 수 있는지가 핵심 쟁점이 된 이유입니다.
전 세계 인구의 절반 이상이 두 개 이상의 언어를 구사합니다. 이들은 일상 대화나 고객 상담에서 상황에 따라 언어를 자유롭게 전환하며 소통합니다.
하지만 기존 음성 인식 시스템은 대부분 단일 언어에 최적화되어 있어, 이런 자연스러운 언어 전환을 제대로 파악하지 못하는 경우가 많았습니다.
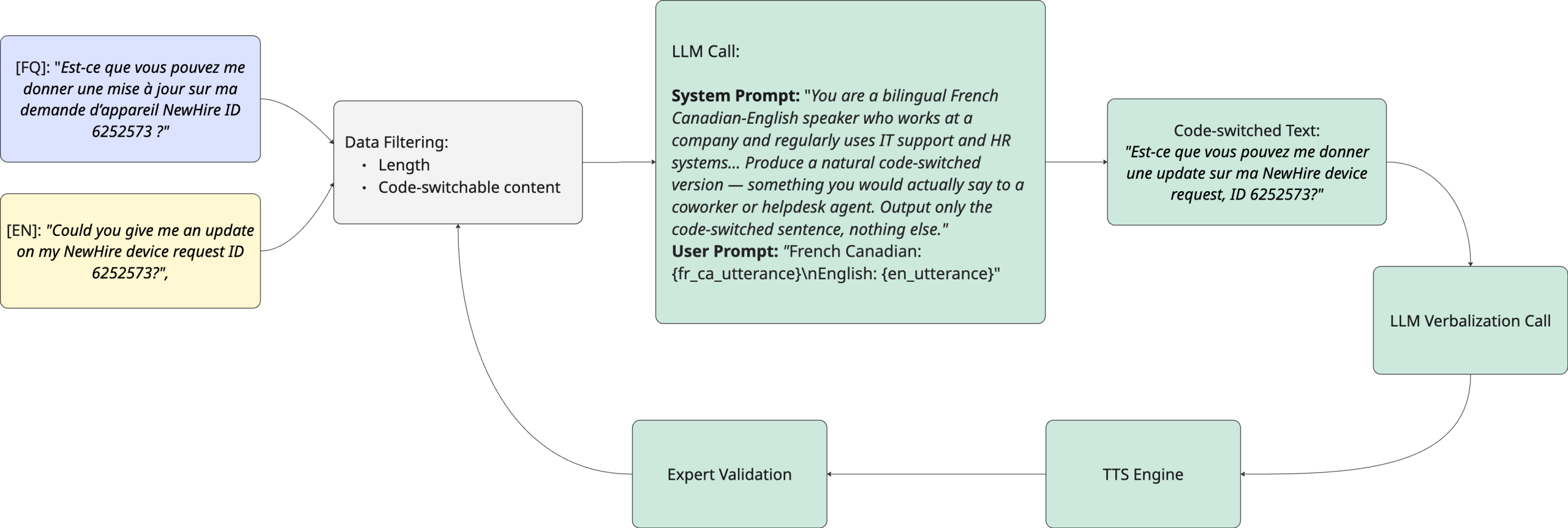
실제 서비스Now AI가 Hugging Face 블로그를 통해 공개한 벤치마크는 이 문제를 구체적으로 다뤘습니다. 스페인어와 영어 등 주요 언어 쌍을 대상으로 자동 음성 인식 모델의 성능을 평가한 결과, 코드스위칭이 발생할 때 오류율이 눈에 띄게 증가하는 것으로 나타났습니다.
특히 기업 환경에서는 인식된 텍스트가 이후 모든 처리 과정에 영향을 미칩니다. 티켓이 잘못 분류되거나 정책 질문이 오해받는 경우 실제 운영 비용으로 직결되기 때문에, 초기 전사 단계의 정확도가 매우 중요합니다.
단순한 기술적 호기심을 넘어 비즈니스 리스크 관리 차원에서 이 문제가 주목받는 것입니다.
이번 벤치마크는 단순히 모델 성능을 나열하는 것을 넘어, 이중언어 환경에서 발생하는 추가 비용과 시스템이 어디서 무너지는지 분석했습니다. 특히 스페인어-영어 조합처럼 실제 고객 문의가 많은 언어 쌍을 중심으로 데이터를 구축한 점이 특징입니다.
앞으로 음성 에이전트를 도입하려는 기업들은 단일 언어 모델의 성능만 보지 말고, 자사 고객층이 주로 사용하는 언어 조합에서의 코드스위칭 처리 능력을 반드시 확인해야 합니다. 기술이 빠르게 발전하고 있지만, 실제 다국어 환경에서의 안정성은 여전히 검증이 필요한 영역입니다.