인공지능 모델이 처리해야 할 데이터 양이 폭발적으로 증가하면서 개발자들은 토큰 비용이라는 새로운 부담을 안게 되었습니다. 특히 RAG나 복잡한 도구 호출이 필요한 환경에서는 불필요한 정보까지 모두 모델에 전달되면서 비용이 급증하는 문제가 발생했습니다.
바로 이때 등장한 ‘헤드룸’이 개발자들의 시선을 사로잡고 있습니다.
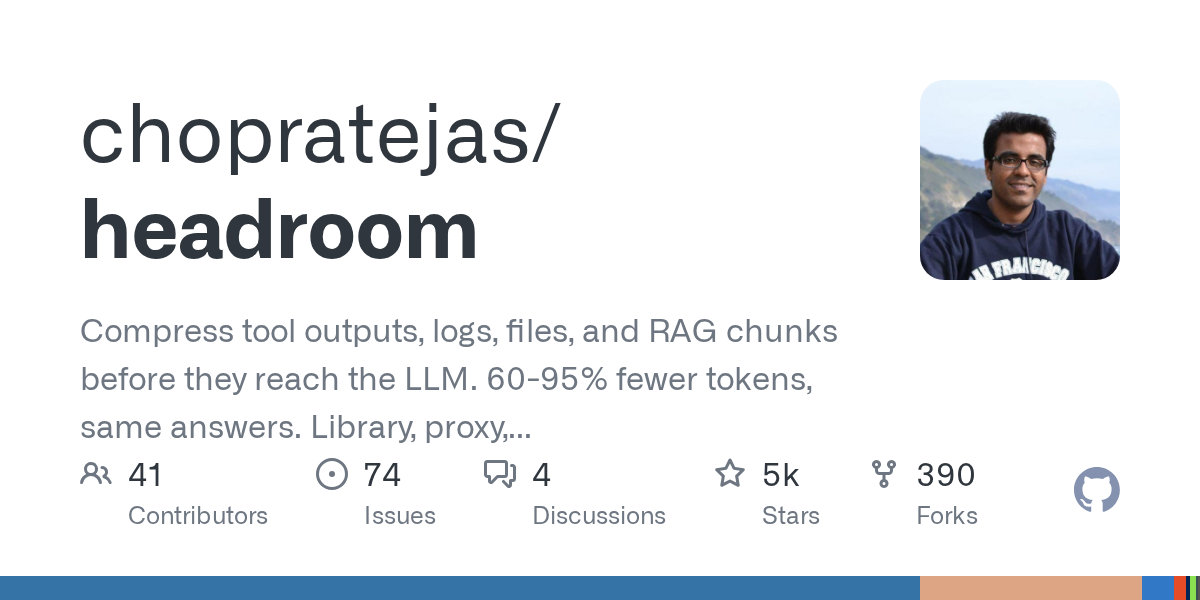
이 도구의 핵심은 LLM에 도달하기 전 도구 출력물, 로그, 파일, 그리고 RAG 청크를 압축하는 것입니다. 놀라운 점은 압축률이 60%에서 95%에 달하면서도 최종 답변의 정확도는 그대로 유지된다는 사실입니다.
마치 짐을 줄이되 내용물은 그대로 남기는 효율적인 여행 가방과 같은 역할을 합니다.
개발자 커뮤니티에서는 이 기술이 단순한 압축을 넘어 ‘컨텍스트 최적화 레이어’로 불리며 주목받고 있습니다. 데이터베이스 쿼리나 파일 읽기 등 에이전트가 수행하는 모든 작업의 맥락을 최적화하여 불필요한 토큰 소모를 막아줍니다.
이는 특히 대규모 프로젝트를 운영하는 기업이나 스타트업에게 실질적인 비용 절감 효과를 가져다줍니다.
현재 이 프로젝트는 라이브러리, 프록시, MCP 서버 등 다양한 형태로 제공되며 로컬 환경에서도 작동합니다. GitHub 트렌딩 차트에서 상위권을 차지하며 많은 개발자가 포크하고 기여하고 있는 모습은 이 기술이 가진 잠재력을 방증합니다.
단순한 유행을 넘어 AI 인프라의 효율성을 높이는 필수 도구로 자리 잡을 가능성이 큽니다.
앞으로 이 기술이 어떻게 발전할지, 그리고 실제 상용 서비스에서 얼마나 널리 적용될지 지켜볼 필요가 있습니다. AI 비용 구조가 변화하는 시점에서 헤드룸 같은 도구는 개발 워크플로우의 표준이 될 수도 있습니다.
비용 부담 없이 더 정교한 AI 모델을 활용하고 싶은 이들에게는 반드시 체크해봐야 할 트렌드입니다.