최근 글로벌 채용 시장에서 가장 뜨거운 감자는 알고리즘이 만들어낸 ‘단일화 현상’입니다. 수많은 기업이 동일한 공급업체의 채용 심사 도구를 사용하면서, 개별 기업의 고유한 판단 기준이 사라지고 시스템 전체가 균일한 결과를 내놓는 상황이 벌어지고 있습니다.
이는 마치 부동산 시장에서 특정 알고리즘이 임대료를 획일화했던 사례와 유사하게, 채용 기회라는 자원이 특정 방식으로만 배분되는 독점적 구조를 형성하고 있습니다.
실제 데이터를 살펴보면 미국 내 고용주 90% 이상이 알고리즘을 통해 지원자를 선별하며, 포춘 100대 기업의 60% 이상은 하이어뷰 같은 특정 벤더의 기술을 도입했습니다. 이렇게 소수의 알고리즘이 시장을 장악할 때 발생하는 문제는 단순히 효율성 향상이 아닙니다.
한 벤더의 시스템이 여러 기업에 적용되면, 지원자의 이력서 점수가 3 개에서 12 개월 동안 캐시되어 동일한 점수가 반복적으로 부여되는 현상이 발생합니다. 이는 지원자가 다른 회사에 지원하더라도 이전의 평가 결과가 그대로 따라다니는 불합리한 상황을 낳습니다.
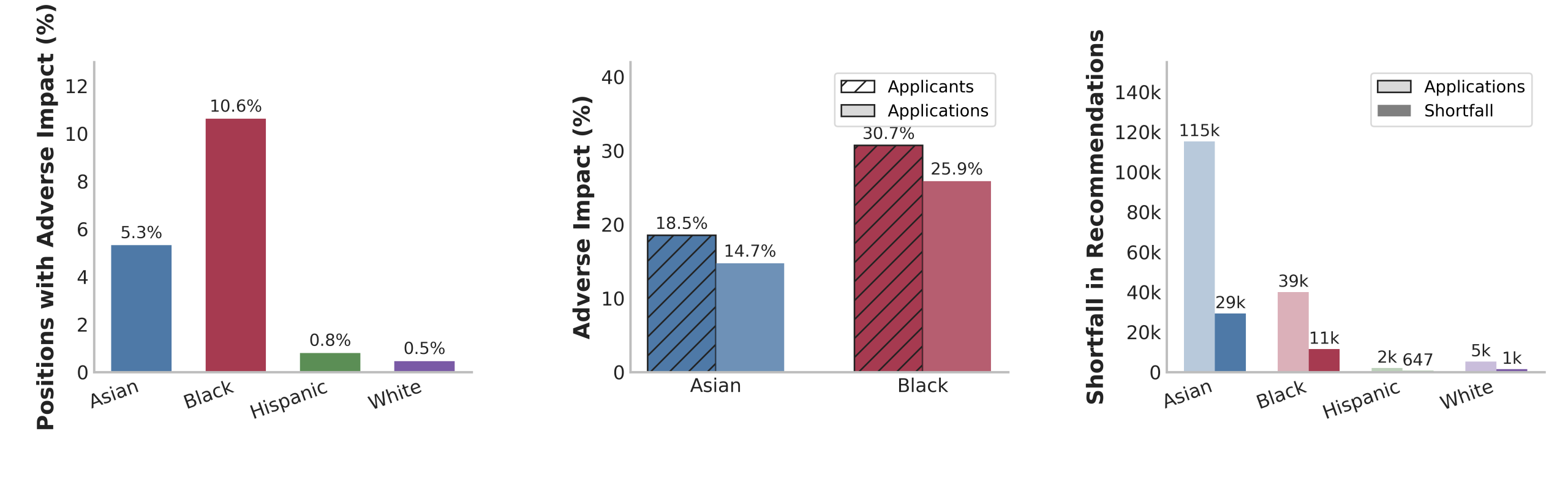
이러한 알고리즘의 단일화가 인종별 편차로 이어진다는 사실은 최근 대규모 실증 연구에서 명확히 드러났습니다. 340 만 명의 지원자와 400 만 건의 지원 데이터를 분석한 결과, 아시아계와 흑인 지원자가 특정 직무에서 불리한 영향을 받는 비율이 각각 14.74% 와 25.87% 에 달했습니다.
특히 아시아계 지원자의 경우, 가장 높은 선발률을 보인 그룹과 동일한 비율로 선발된다면 약 2 만 9 천 건의 추가 지원이 합격으로 이어졌을 것으로 추정됩니다. 이는 알고리즘이 인종적 특성을 직접적으로 반영하지 않더라도, 데이터의 편향이나 평가 기준의 균일성 때문에 특정 집단에게 체계적인 불이익을 줄 수 있음을 시사합니다.
더욱 우려스러운 점은 지원자가 여러 직무에 지원하더라도 동일한 결과를 반복적으로 받는 ‘동질적 결과’가 빈번하게 나타난다는 것입니다. 10 개 직무에 지원한 지원자 중 4% 는 모든 직무에서 일관되게 탈락 판정을 받았습니다.
이는 우연히 발생할 확률보다 훨씬 높은 수치로, 알고리즘이 특정 지원자를 일괄적으로 배제하는 경향이 있음을 보여줍니다. 만약 이 시스템이 실제로 직무 수행 능력을 예측하는 데 유효하다면 문제없겠지만, 현재로서는 알고리즘이 실제 업무 성과와 얼마나 연동되는지에 대한 검증이 부족합니다.
앞으로 주목해야 할 점은 이러한 알고리즘적 단일화가 고용 시장의 다양성을 어떻게 재편할지입니다. 현재는 미국 민권법 제 7 조의 ‘부정적 영향’ 기준을 적용해 인종별 편차를 검증하는 단계이지만, 향후에는 알고리즘이 캐싱한 점수가 지원자의 경력 전체를 어떻게 규정할지가 핵심 쟁점이 될 것입니다.
기술적 효율성을 명분으로 한 시스템의 확산이 결국은 인재 풀을 좁히고 특정 집단을 배제하는 새로운 형태의 장벽이 되지 않도록, 평가 기준의 투명성과 검증 가능성에 대한 사회적 논의가 본격화되어야 합니다.






